'분류 전체보기'에 해당되는 글 243건
- 2009.05.18 :: Relationship에 관하여
- 2009.05.18 :: Entity에 관하여
- 2009.05.18 :: HTTP 인증을 요구하는 페이지의 컨텐츠에 접근하기
- 2009.05.18 :: jQuery Tutorial - 2
- 2009.05.18 :: jQuery Tutorial - 1
- 2009.05.17 :: log4j.properties 사용 방법
- 2009.05.17 :: 자바 파일 압축하기
- 2009.05.17 :: 이클립스에서 JVM terminated. Exit code=-1 경고창 뜰때
- 2009.05.17 :: 자바 기본 환경 설정.....
- 2009.05.17 :: 옵저버 패턴
- 2009.05.17 :: [Design Patterns] Strategy Pattern 4
- 2009.05.17 :: [Design Patterns] Strategy Pattern 3
- 2009.05.17 :: [Design Patterns] Strategy Pattern 2
- 2009.05.17 :: [Design Patterns] Strategy Pattern 1
- 2009.05.17 :: java.util.regex.PatternSyntaxException: Unclosed group near index 1
- 2009.05.15 :: HEAD FIRST DESIGN PATTERNS
- 2009.05.15 :: 오라클 데이터베이스 모델링 & 성능 설계
- 2009.05.15 :: JAVA - TCP 소켓 프로그램 예제의 흐름
- 2009.05.15 :: JAVA - TCP 소켓프로그램 예제
- 2009.05.15 :: Protocol 설계를 이용한 로그인 인증예제 (소켓, 프로토콜, 바이트스트림)
- 2009.05.15 :: 가볍고 쉬운 Ajax - jQuery 시작하기
- 2009.05.15 :: jQuery의 기본이 되는 jQuery/Core에 대해 알아보자!!
- 2009.05.15 :: JQuery란 과연 무엇인가?
- 2009.05.14 :: SQL 실행순서
- 2009.05.14 :: 입력상자 한글/영문 설정하기
- 2009.05.14 :: 숫자인지 문자인지 판별하기 (JAVA)
- 2009.05.14 :: iBATIS기초 - JNDI설정
- 2009.05.11 :: 일반 문자열을 프로그래밍 언어에서 사용하는 문자열로 변경하기 SQL, StringBuffer
- 2009.05.10 :: 서블렛 + JDBC 연동시 코딩 고려사항 -제2탄-
- 2009.05.10 :: 서블렛 + JDBC 연동시 코딩 고려사항 -제1탄-
cardinality
엔티티 인스턴스가 다른 엔티티 타입의 엔티티 인스턴스와 맺을 수 있는 릴레이션쉽 인스턴스의 수효
optionality
엔티티 인스턴스가 다른 엔티티 타입의 엔티티 인스턴스와 맺어야 하는 관계가 필수인지 선택인지 표시
카디널리티와 옵셔널리티
엔티티간 단방향 표시 (사용안함)
엔티티간 양방향 표시 (양방향으로 표시)
엔티티 타입이 분류된 정보의 집합체를 총칭한다면, 엔티티 인스턴스(entity instance)는 엔티티 타입에 포함되어 있는 낱개의 정보를 의미
Entity 분류
엔티티 타입은 사물, 사건, 개념 등의 3가지 범주로 분류
- 사물 : 형체를 갖고 있는 정보
ex) 고객, 직원, 대리점 ...
- 사물 엔티티 타입은 다른 범주에 속해 있는 엔티티 타입 보다는 도출이 용이
- 엔티티 인스턴스의 발생이 빈번하지 않으며 변경되거나 없어지지 않으면서 계속 활용
- 다른 엔티티 타입보다는 우선적으로 도출되어야 함.
- 사물 엔티티 타입의 구조 변경은 전체 데이타 모델에 심각한 영향을 미치므로 신중하게 검토한 후 엔티티 타입의 구조를 결정하여야
- 사건 : 기업 활동을 통해서 생성되고 활용되는 정보들
ex) 주문, 구매, 판매, 청구 ...
- 해당 업무에 대한 정확한 지식을 갖고 있어야만 도출이 가능
- 정보 활용을 극대화하기 위해서는 정보를 분류하는 기준이 모든 엔티티 타입에 일관되게 적용되어야 함.
- 엔티티 인스턴스의 발생이 빈번하며, 한번 생성된 엔티티 인스턴스도 자주 변경
- 엔티티 인스턴스의 수효가 많으며 항상 증가하게 되므로, 오래된 정보는 주기적으로 정리하는 것이 바람직
- 개념 : 기업의 필요에 의하여 임의적으로 만들어진 개념
ex) 부서, 코드, 고객군, 상품군 ...
- 도출이 어려울 뿐만 아니라, 시간이 지남에 따라 개념이 변경되거나 추가되는 등 엔티티 타입 자체의 안정성이 보장되지 않는다
- 기업의 시각에서 관찰하기 위하여 추가되는 경우가 대부분
- 엔티티 인스턴스나 엔티티 타입의 변동이 기업의 정책 변경이나 환경 변경 시에만 이루어지며, 그 이외에는 거의 변동되지 않는다
필요한 코드는 다음과 같다.
HttpURLConnection connection = (HttpURLConnection)url.openConnection();
connection.setRequestProperty("Authorization", "Basic " +
new sun.misc.BASE64Encoder().encode("[아이디]:[비밀번호]".getBytes()));
이 렇게 작성한 다음 인증 정보를 요청 property에 지정하였으므로 connection 객체를 통해서 InputStream 타입으로 읽어오면 원하는 컨텐츠에 접근하여 데이터를 가져올 수 있다. setRequestProperty에는 여러가지 요청정보를 추가할 수 있는데, 일단 가장 필요한 내용은 인증 정보이므로 다른건 나도 잘 모르겠고, 간단한 작업을 하는덴 그리 필요하진 않은 것 같다...
그런데 "Basic"이라는 건 인증 수준을 나타내는 건가? 검색해 보니... RFC 2617에 Basic은 클라이언트가 아이디와 패스워드를 각각의 영역에 접근하기 위해 제공해야 하는 모델에 기반한 인증 스키마라고 한다. 아래는 RFC 2617의 원문중....
"opaque string"이란 단어가 나오는데... BASE64Encoder로 인코딩해서 리턴되는 문자열을 가리키는 것 같다.
출처 : http://docs.jquery.com/Tutorials:Getting_Started_with_jQuery#Rate_me:_Using_Ajax
다음은 jQuery에서 Ajax를 사용하는 예제인데 http://jquery.bassistance.de/rate.phps 페이지에 접근하여 average와 count를 가져오는 예제임.
$(document).ready(function() {
// 마크업 생성
$("#rating").append("Please rate: ");
for ( var i = 1; i <=5; i++
$("#rating").append("<a href='#'>" + i + "</a> ");
// 마크업을 컨테이너에 추가한 후 클릭 핸들러를 적용
$("#rating a").click( function(e) {
// 요청 전송
$.post("rate.php", {rating: $(this).html()}, function(xml) {
// 출력 결과 포매팅
$("#rating").html(
"Thanks for rating, current average: " + $("average", xml).text() +
", number of votes: " + $("count", xml).text()
);
});
return false;
});
});
Ajax를 이용하여 불러오는 컨텐츠에 이벤트 핸들러를 등록할 경우 발생할 수 있는 문제는 컨텐츠가 모두 불러오지 못한 상태에서 이벤트를 등록하지 못해서 발생하는 문제인데, 이러한 문제는 함수를 위임하여 처리할 수 있음.
function addClickHandlers() {
$("a.remote", this).click( function() {
$("#target").load(this.href, addClickHandlers);
});
}
$(document).ready(addClickHandlers);
jQuery에서는 document의 ready 이벤트를 다음과 같이 등록한다.
$(document).ready(function() {
// DOM이 준비된후 할일 정의
});
링크를 클릭했을 때 경고창으로 메시지를 띄우는 예제.
$(document).ready(function() {
$("a").click(function() {
alert("Hello, world!");
});
});
$("a") 는 jQuery의 선택자(selector)이며 $는 jQuery의 클래스이므로 $()는 새로운 jQuery 객체를 생성하는 코드임. click은 jQuery 객체의 메소드로서 클릭 이벤트와 바인딩되어 이벤트 발생시 해당 메소드의 내용을 실행.
document.getElementById("orderedlist")와 같은 코드를 jQuery에서는 다음과 같이 쓸 수 있음.
$(document).ready(function() {
$("#orderedlist").addClass("red");
});
아래는 li의 모든 child 중에서 orderedlist라는 id를 가지는 노드를 선택하여 "blue" 클래스를 추가하는 코드임.
$(document).ready(function() {
$("#orderedlist > li").addClass("blue")
});
아래는 사용자가 리스트의 가장 마지막 li 엘리먼트위에 마우스를 갖다대었을 때 클래스를 추가하고 제거하는 코드임.
$(document).ready(function() {
$("#orderedlist li:last").hover(function() {
$(this).addClass("green");
}, function() {
$(this).removeClass("green");
});
});
find() 메소드는 이미 선택된 엘리먼트의 자식들을 찾으며, each()는 모든 엘리먼트들을 순회하면서 주어진 작업을 수행.
$(document).ready(function() {
$("#orderedlist").find("li").each(function(i) {
$(this).append(" BAM! " + i);
});
});
jQuery에서 다루고 있지 않은 메소드를 호출하고자 할 때는 다음과 같이 코드를 작성.
$(document).ready(function() {
$("#reset").click(function() {
$("#form")[0].reset();
});
});
한번에 여러 폼을 reset하고자 할 때.
$(document).ready( function() {
$("#reset").click( function() {
$("#form").each( function() {
this.reset();
});
});
});
위 경우 this는 실제적인 엘리먼트를 가리킴.
특정 그룹에서 비슷하거나 같은 엘리먼트들 중에서 특정 엘리먼트만 골라내기.
$(document).ready(function() {
$("li").not("[ul]").css("border", "1px solid black");
});
모든 li 엘리먼트들 중에서 ul엘리먼트를 자식으로 갖지 않는 엘리먼트를 골라냄.
$(document).ready(function() {
$("a[@name]").css("background", "#eee");
});
위 코드는 name 속성을 가지는 모든 앵커 엘리먼트에 배경색상을 추가함.
$(document).ready(function() {
$("a[@href*=/content/gallery]").click(function() {
// /content/gallery를 가리키는 모든 링크에서 수행할 작업
});
});
형제 엘리먼트에 접근하여 작업 처리하기.
$(document).ready( function() {
$("#faq").find('dd').hide().end().find('dt').click( function() {
$(this).next().slideToggle();
});
});
부모 엘리먼트에 접근하여 작업 처리하기.
$(document).ready( function() {
$("a").hover( function() {
$(this).parents("p").addClass("highlight");
}, function() {
$(this).parents("p").removeClass("highlight");
});
});
다음은 $(document).ready(callback) 표기의 줄임 표현임.
$(function() {
// DOM이 준비되었을 때 실행할 코드
});
줄임 표현을 이용하여 Hello, world! 예제를 재작성.
$( function() {
$("a").click( function() {
alert("Hello, world!");
});
});
ERROR : 일반 에러가 일어 났을 때 사용합니다.
WARN : 에러는 아니지만 주의할 필요가 있을 때 사용합니다.
INFO : 일반 정보를 나타낼 때 사용합니다.
DEBUG : 일반 정보를 상세히 나타낼 때 사용합니다.
ConversionPattern 사용 방법
%m 로그내용이 출력됩니다
%d 로깅 이벤트가 발생한 시간을 기록합니다.
포맷은 %d{HH:mm:ss, SSS}, %d{yyyy MMM dd HH:mm:ss, SSS}같은 형태로 사용하며 SimpleDateFormat에 따른 포맷팅을 하면 된다
%t 로그이벤트가 발생된 쓰레드의 이름을 출력합니다.
%% % 표시를 출력하기 위해 사용한다.
%n 플랫폼 종속적인 개행문자가 출력된다. rn 또는 n 일것이다.
%c 카테고리를 표시합니다
예) 카테고리가 a.b.c 처럼 되어있다면 %c{2}는 b.c가 출력됩니다.
%C 클래스명을 포시합니다.
예)클래스구조가 org.apache.xyz.SomeClass 처럼 되어있다면 %C{2}는 xyz.SomeClass 가 출력됩니다
%F 로깅이 발생한 프로그램 파일명을 나타냅니다.
%l 로깅이 발생한 caller의 정보를 나타냅니다
%L 로깅이 발생한 caller의 라인수를 나타냅니다
%M 로깅이 발생한 method 이름을 나타냅니다.
%r 어플리케이션 시작 이후 부터 로깅이 발생한 시점의 시간(milliseconds)
%x 로깅이 발생한 thread와 관련된 NDC(nested diagnostic context)를 출력합니다.
%X 로깅이 발생한 thread와 관련된 MDC(mapped diagnostic context)를 출력합니다.
log4j.properties 파일 사용 예
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[COTAMOT] %5p,[%d],[%t],(%F:%L),%m%n
log4j.appender.stdout.target=System.err
#rolling 어펜더는 파일로 처리한다라고 정의
log4j.appender.rolling=org.apache.log4j.DailyRollingFileAppender
#로그 파일 이름은 output.log
log4j.appender.rolling.File=output.log
#true면 WAS를 내렸다 올려도 파일이 리셋되지 않습니다.
log4j.appender.rolling.Append=true
#파일 최대 사이즈는 500KB로 설정
log4j.appender.rolling.DatePattern='.'yyyy-MM-dd
#rolling 어펜더는 패턴 레이아웃을 사용하겠다고 정의
log4j.appender.rolling.layout=org.apache.log4j.PatternLayout
#rolling 어펜더는 패턴 레이아웃 포맷
log4j.appender.rolling.layout.ConversionPattern=[COTAMOT] %5p,[%d],[%t],(%F:%L),%m%n
자바 파일 압축하기 소스를 만들어 보았다.
기본적으로 주석들이 영어인 이유는…… 그냥 api에서 해당 함수들에 대한 설명을 긁어왔기 때문이니….
알아서 해석하시길…ㅎㅎ
package com.eunicon.common.util;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
public class MakeZip {
public void compress(String[] source, String target){
byte[] buf = new byte[1024];
try {
// for writing files in the ZIP file format.
ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(target));
// source라는 문자 배열에 정의된 파일 수 만큼 파일들을 압축한다.
for (int i = 0; i < source.length; i++) {
FileInputStream in = new FileInputStream(source[i]);
/* Begins writing a new ZIP file entry and positions the stream to the start of the entry data.
* new ZipEntry(source[i]) : the ZIP entry to be written.
*/
zipOut.putNextEntry(new ZipEntry(source[i]));
int len;
while ((len = in.read(buf)) > 0) {
/* Writes an array of bytes to the current ZIP entry data.
*
* buf : the data to be written.
* 0 : the start offset in the data.
* len : the number of bytes that are written.
*/
zipOut.write(buf, 0, len);
}
// Closes the current ZIP entry and positions the stream for writing the next entry.
zipOut.closeEntry();
in.close();
}
// Closes the ZIP output stream as well as the stream being filtered.
zipOut.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
/* 압축할 원본 파일들
* WINDOWS 파일 시스템을 기준으로 한 절대경로로 지정함.
*/
String[] source = new String[] {
"D:\\DownLoads\\smsp2.gif",
"D:\\DownLoads\\2008_03_IMG_6449.jpg",
"D:\\DownLoads\\2008_03_IMG_6244.jpg" };
// 압축 파일이 저장될 target을 지정한다.
String target = "D:\\DownLoads\\20090109.zip";
MakeZip makeZip = new MakeZip();
makeZip.compress(source, target);
}
}
일명 GANYMEDE.....
압축을 풀고 파일을 실행시키니 이게 왠일?
다음과 같은 창이 뜨면서 실행이 되지 않았다.

당황해서 이리저리 찾아보니, vm을 설정해 주면 된다고 한다.
이클립스가 설치된 폴더로 가서 eclipse.ini 파일을 찾아서 열면 아래와 같이 설정되어 있다.

찾아보니 -Xmx512m 를 -Xmx128m 이나 -Xmx256m으로 바꿔줘도 해결이 가능하다고 한다.
하지만 필자는 -vm을 아래와 같이 설정했다.

위와 같이 수정 -> 저장 후 이클립스를 다시 시작하니 정상적으로 이클립스가 실행되는 것을 확인했다.
역시 사람은 알아야 하는 것 같다.
배우고 또 배우자...!!!!
초심이 점점 변하면서 날이 갈수록 게을러 지는거 같다...
무엇인가를 포스팅하고 싶은데 마땅히 할게 없어서 자바 기본 세팅에 대해 포스팅 해보고자 한다.
환경설정을 위해 우선 내컴퓨터 - 마우스 오른쪽 클릭 - 속성으로 이동한다.
속성 - 고급 - 환경변수를 클릭한다.
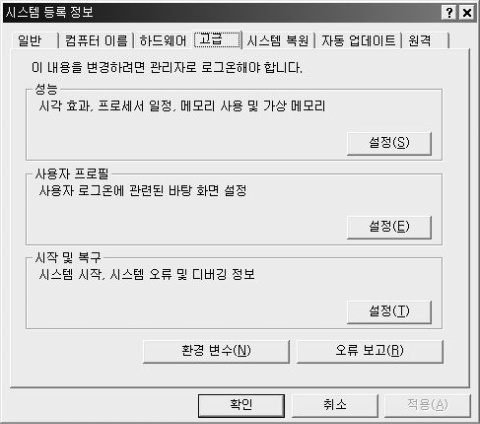
아래와 같이 환경변수 창이 뜨는 것을 확인할 수 있다.
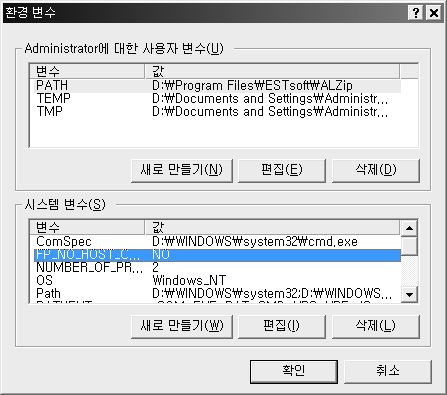
프로그램 전반에 걸쳐 사용할 것들이 있다면 Administrator에 정의 하면되고, 해당 사용자에 대해서 설정할 것이라면 시스템변수에 설정하면 된다. 필자는 시스템 변수에 설정할 것이다.
아래 그림에서 시스템 변수의 새로 만들기 버튼을 클릭한다.
먼저 JAVA_HOME을 설정한다.
JAVA_HOME은 jdk가 설치된 폴더의 위치를 의미한다.
간혹 JRE가 설치된 폴더와 착각하는 사람들이 있는데 혼동하지 말자!!!
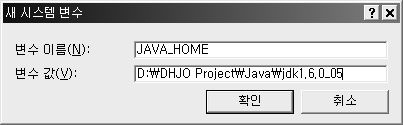
아래 그림과 같이 JAVA_HOME일 설정된 것을 확인 할 수 있다.
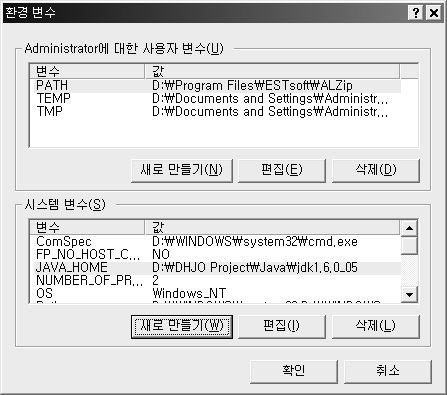
JAVA_HOME이 설정되었다면 다음은 path를 설정해 보자.
시스템변수 창에서 Path항목을 더블클릭 하면 아래와 같은 창이 뜬다.
Path의 가장 앞에 %JAVA_HOME%\bin; 이라고 타이핑하자.
가장 앞에 놓는 이유는 JDK가 오라클이나 기타 다른 프로그램에서 다른 버전으로 사용할 수도 있기 때문이다.
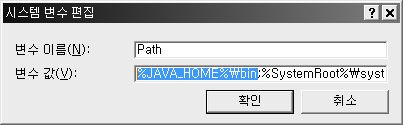
설정을 마쳤다면 확인해 봐야 한다.
아래 그림과 같이 실행창을 띄운다.
실행창은 윈도우키 + r 을 누르면 뜬다.
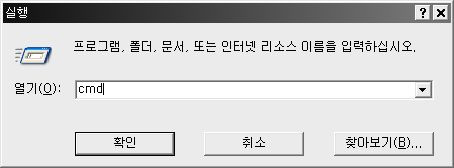
java -version 이라고 typing해보자.
이 명령은 jre를 통해 해당 자바 실행 환경의 버전을 확인할 수 있다.
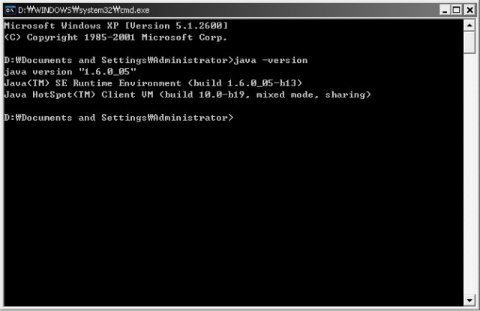
자바의 버전을 확인 했다면 이번에는 JDK가 환경세팅에서 정상적으로 세팅되었는지 확인하기 위해 javac 라고 typing해보자.
아래 그림과 같이 여러가지 옵션들이 출력된다면 정상적으로 JDK가 환경설정에 등록된 것이다.
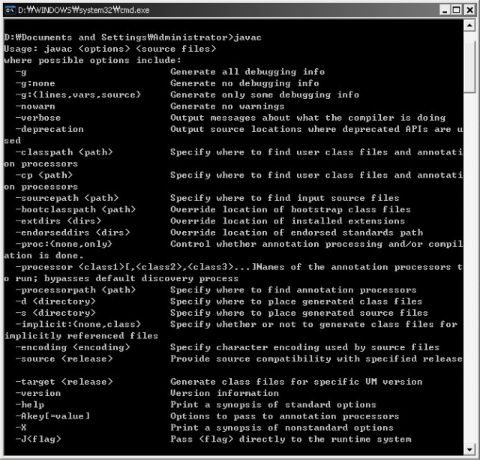
이상으로 자바 환경 설정에 대해 간단히 알아 보았다.
오늘 보려고 하는 내용은 옵저버 패턴이다.
옵저버 패턴의 정의는 다음과 같다.
옵저버 패턴(Observer Pattern)에서는 한 객체의 상태가 바뀌면 그 객체에 의존하는 다른 객체들에게 연락이 가고 자동으로 내용이 갱신되는 일대다(one-to-many) 의존성을 정의합니다.
처음 보는 사람들은 저게 무슨말인지 도통 모를것 같다. 이 글만 읽고도 안다면 능숙한 개발자이거나 개발을 하면 크게 될 사람이라고 생각한다..ㅋㅋㅋ (ㅡㅡ;;)
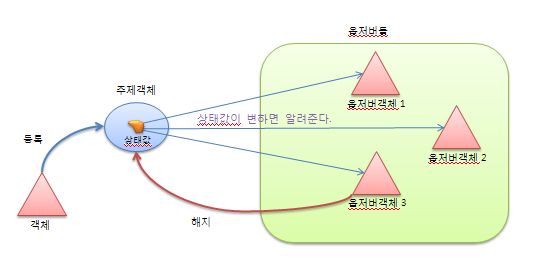
간단히 풀어서 설명하면, 옵저버 패턴에서는 상태를 저장하고 있는 주제객체와 주제객체가 가지고 있는 상태값에 의존하는 옵저버들이 있다.
1. 주제 객체가 생성되어 서비스를 시작한다.
2. 옵저버 객체가 되기 위해 주제 객체에 옵저버 객체로 등록한다.
3. 옵저버 객체에서 탈퇴하고자 주제 객체에서 해지한다.
위의 순서를 그림으로 표현하면 아래와 같다.
다음 포스팅에서는 옵저버 패턴을 이용한 소스코드를 작성해 보자!!!
이전 포스팅을 동적으로 나는 행위와 우는 행위를 바꿀수 있도록 수정해 보자.
클래스 다이어 그램은 다음과 같다.
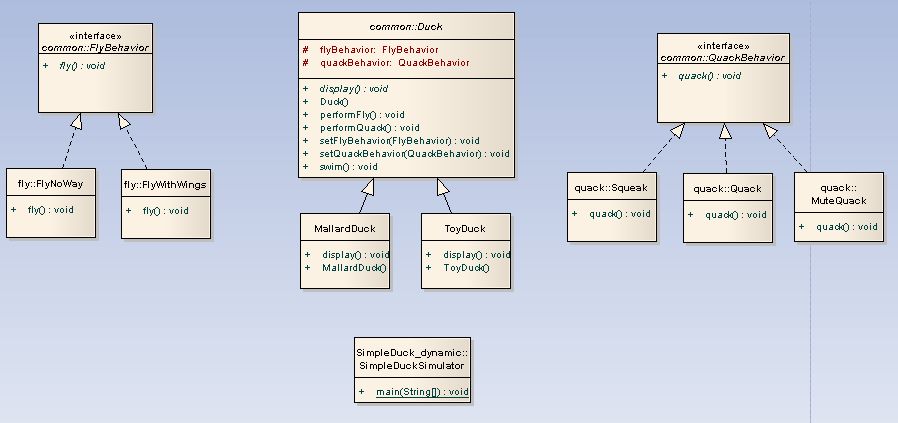
수정해야 할 내용은 다음과 같다.
1. Duck클래스에 2개의 세터메소드를 추가해준다.
setFlyBehavior(), setQuackBehavior()
2. 시뮬레이션 프로그램에서 원하는 메소드를 호출한다.
소스가 필요한 사람을위해 소스 추가해 놓는다.
 src.zip
src.zip이전 포스팅에서 만든 프로그램의 문제점에 대해 다시 정리해 보자.
자바 인터페이스에는 구현된 코드가 전혀 들어가지 않기때문에 코드 재사용을 할 수가 없다. 즉, 한 행동을 바꿀때마다 그 행동이 정의 되어 있는 모든 서브클래스들을 일일이 수정해줘야 하는데, 이는 새로운 버그를 발생시킬 확률이 높다.
이러한 상황에 어울리는 디자인 원칙은 다음과 같다.
"바뀌는 부분을 바뀌지 않는 부분과 분리해서 캡슐화 시킨다. 그렇게 하면 나중에 바뀌지 않는 부분에는 영향을 미치지 않은채로 그 부분만 고치거나 확장할 수 있다."
무슨 뜻인지 이해가 가는지...?? ㅋㅋㅋ
클래스 다이어 그램을 먼저 보면서 이해해 보자.
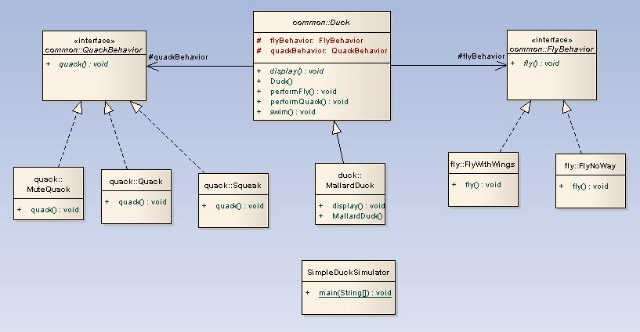
위에서 말한 디자인 원칙에 따르면, 자주 변하는 부분은 fly()와 quack() 이다.
이 부분들을 Duck 클래스와 분리하려면, 나는것과 관련된 집합과 우는것과 관련된 집합. 즉, 두 개의 클래스 집합(set)을 만들어야 한다.
그리고 각 클래스 집합에는 각각의 행동을 구현한 것을 모두 집어 넣으면 된다.
(ex 꽥꽥거리는 클래스, 삑삑거리는 클래스, 소리는 내지 않는 클래스 ... etc)
두개의 클래스 집합을 만들어야 한다는 것을 알았다면 다음으로 알아야 할 것이 무었일까??
바로 최대한 유연하게 코드를 작성해야 한다는 것이다. 처음부터 이런 문제가 발생한 원인은 오리의 행동인 fly()와 quack()가 유연하지 않았기 때문이었다.
추가로 Duck의 인스턴스에 행동을 할당할 수 있어야 한다. (이해가 힘들다면 소스를 확인해 보길...설명하기 귀찮아 지기 시작함..ㅡㅡ;;)
위와 같이 유연하게 코드를 작상하고자 한다면, 구현이 아닌 인터페이스에 맞춰서 프로그래밍해야 한다.
인터페이스에 맞춰 프로그래밍한다는 말은 자바의 인터페이스를 사용하라는 의미일 수도 있지만, 조금더 깊게 의미를 생각하면, 상위 형식에 맞춰서 프로그래밍함으로써 다형성을 활용해야 한다는 것을 의미한다.
그래서 위 다이어 그램과 같이 FlyBehavior인터페이스를 구현한 클래스 집합과 QuackBehavior인터페이스를 구현한 클래스 집합을 만든 것이다.
이런식으로 디자인 한다면, 다른 형식의 객체에서도 나는 행동과 꽥꽥 거리는 행동을 재사용 할 수가 있다.
음....추가로 설명해야 할 것들이 상당히 있지만, 역시나 공부한 내용을 다시 설명하는 것은 정말이지 어려운 것 같다. 새삼 선생님들을 존경하게 되었다는...ㅡㅡ;;;
마지막으로 소스하나를 올리고 이번 포스팅을 마치고자 한다.
이전 포스팅에서 구현한 프로그램의 문제점에 대해서 생각해 보자
간단한 예를 들어서 문제를 집어보겠다.
오리 시뮬레이션에서 오리가 하늘을 날 수 있도록 하고 싶을때 어떻게 구현해야 할까??
첫번째로 생각해 볼 수 있는것은 super class인 Duck 클래스에 fly()를 추가해주는 것이다.
누구나 가장 먼저 이 생각을 하지 않을까 싶다.
하지만 이렇게 할 경우, 하늘을 날지 않는 나무 오리라든가 고무 오리마저 하늘을 나는 경우가 발생한다.
나무 오리나 고무 오리가 하늘을 날지 못하게 하려면 별 수 없이 overriding(재정의)를 해야 한다.
거기에다가 나무 오리의 경우는 꽥꽥거리지 못하게 quack()도 overriding해줘야 한다.
이렇게 super class에 의존도가 높아지는 코딩을 한다면 다음과 같은 단점이 생긴다.
1. 서브 클래스에서 코드가 중복된다.
2. 실행시에 특징을 바꾸기 힘들다.
3. 모든 오리들의 행동을 알기 힘들다.
4. 코드를 변경했을 때 다른 오리들한테 원치 않은 영향을 끼칠수 있다.
만약 프로그램을 자주 갱신해야 한다면, 정말이지 위와 같은 방법으로 코딩하는 것은 개발자를 잡는 일일 것이다.
그렇다면 다음으로 생각할 수 있는 것은 무엇일까??
상속을 통해서 되지 않는다면, 다음으로 생각할 수 있는 것은 인터페이스가 아닐까 싶다.
인터페이스를 이용한 클래스 다이어 그램을 보자.
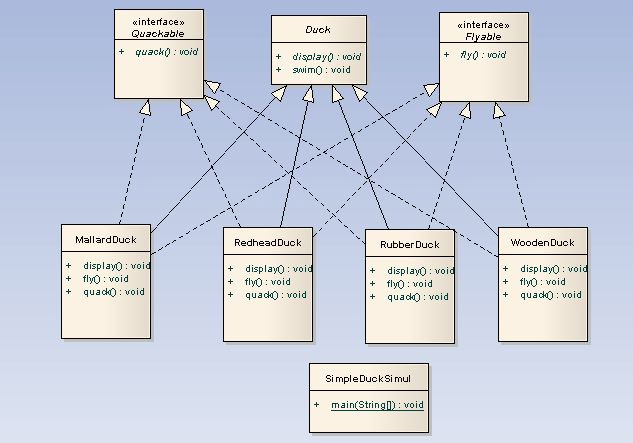
새로운 행동을 추가할때 인터페이스를 따른다면 새로운 클래스를 추가할 때마다 fly()와 quack()메소드를 일일이 살펴보고 상황에 따라 override할 필요는 없을 거 같다.
하 지만 이렇게 구현할 경우 코드가 중복될 수밖에 없다. 또한 수정해야 하는 경우 중복되는 모든 코드들을 수정해야 한다.(ex fly()를 수정해야 할 경우) 즉, 코드 재사용은 생각할 수가 없다는 것이다. 게다가 코드 관리를 하기도 정말이지 힘들 것이다.(오리마다 나는 방식이 모두 다르다면, 모든 오리 클래스에 fly()가 다 다를테니 당연히 관리가 힘들다.)
정말이지 문제점이 많은 것 같다.
그래서 필요한 것이 디자인패턴이 아닌가 싶다.
다음 포스팅에서 이런 문제들을 해결할 Strategy Pattern 에 대해 포스팅 해보겠다.
소스들
 Duck.java
Duck.java포스팅한다는 것이 다른 사람들에게 보여주기 위한 것일수도 있지만,
머 어차피 이 포스팅은 내가 내 만족을 위해서 내 멋대로 적는 것이니 절대로...경어는 안쓴다..ㅡㅡ;;
한동안 머리를 굴리지 않았더만 머리가 녹이 슨 것같다.
그래서 이전에 공부했던 디자인패턴 책을 보면서 포스팅을 시작해 보려 한다.
오늘 포스팅하려는 것은 Head First Design Pattern 의 제일 첫번째 Strategy Pattern에 대해서이다.
본격적으로 스트릿티지 패턴에 들어가기 전에 다음 클래스 다이어 그램을 보자.
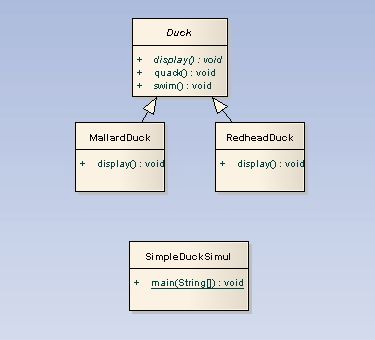
위의 다이어 그램은 간단한 오리 시뮬레이션 프로그램이다.
소스 코드는 첨부 파일을 참조해 주길 바란다.
위의 다이어 그램에 대해 간단히 설명하자면 다음과 같다.
우선 오리의 특성(quack, swimming, shape)을 가진 super class를 만든다.
(오리의 모양은 오리마다 다르므로 추상메소드로 선언한다.)
그리고 물오리, 붉은머리 오리등 오리별로 Duck클래스를 상속받아 개개의 개체를 구현한다.
시뮬레이션을 원하는 오리가 있다면, 시뮬레이션 프로그램에서 구현한다.
(구현한다는 말은 new 연산자를 사용해서 객체를 생성한다는 의미로 보면 된다.)
위의 다이어 그램을 이해하고 문제점을 찾아내는 것이 이번 패턴 공부의 시작이다.
다음 포스팅때가지 각자가 한번 생각해 보길 바란다.
http://eunicon.tistory.com/8
http://eunicon.tistory.com/attachment/hk2.java
http://eunicon.tistory.com/attachment/ik3.java
http://eunicon.tistory.com/attachment/jk1.java
http://eunicon.tistory.com/attachment/hk3.java
java.util.regex.PatternSyntaxException: Unclosed group near index 1
(
^
at java.util.regex.Pattern.error(Pattern.java:1541)
at java.util.regex.Pattern.accept(Pattern.java:1399)
at java.util.regex.Pattern.group0(Pattern.java:2313)
at java.util.regex.Pattern.sequence(Pattern.java:1586)
at java.util.regex.Pattern.expr(Pattern.java:1558)
at java.util.regex.Pattern.compile(Pattern.java:1291)
at java.util.regex.Pattern.<init>(Pattern.java:1047)
at java.util.regex.Pattern.compile(Pattern.java:808)
at eluon.xroshot.util.StringUtil.replaceIgnoreCase(StringUtil.java:321)
at eluon.xroshot.util.StringUtil.xssFilter(StringUtil.java:332)
at eluon.xroshot.action.sms.SendStep1Controller.process(SendStep1Controller.java:80)
at eluon.xroshot.action.BaseController.handleRequestInternal(BaseController.java:514)
at org.springframework.web.servlet.mvc.AbstractController.handleRequest(AbstractController.java:153)
at org.springframework.web.servlet.mvc.SimpleControllerHandlerAdapter.handle(SimpleControllerHandlerAdapter.ja
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:819)
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:754)
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:399)
at org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:354)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:126)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:103)
at com.caucho.server.http.FilterChainServlet.doFilter(FilterChainServlet.java:96)
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:77)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:77)
at com.caucho.server.http.FilterChainFilter.doFilter(FilterChainFilter.java:88)
at com.opensymphony.module.sitemesh.filter.PageFilter.parsePage(PageFilter.java:127)
at com.opensymphony.module.sitemesh.filter.PageFilter.doFilter(PageFilter.java:52)
at com.caucho.server.http.FilterChainFilter.doFilter(FilterChainFilter.java:88)
at com.caucho.server.http.Invocation.service(Invocation.java:315)
at com.caucho.server.http.CacheInvocation.service(CacheInvocation.java:135)
at com.caucho.server.http.HttpRequest.handleRequest(HttpRequest.java:253)
at com.caucho.server.http.HttpRequest.handleConnection(HttpRequest.java:170)
at com.caucho.server.TcpConnection.run(TcpConnection.java:139)
at java.lang.Thread.run(Thread.java:534)
PatternSyntaxException이라... 네이놈에게 물어본 결과 이 녀석은 정규식에서 문법적 에러를 나타내는 unchecked exception이라고 한다. 먼말인지...ㅡㅡ;;;
그래서 일단 프레임워크 쪽 문제라고 보기 힘들어서 우리 소스에서 처음 문제가 발생한 소스로 이동했다.
해당 메소드를 확인해보니, Cross-Site Scripting에 대비해서 문자코드를 변경하는 코드였다.
그렇다면 문자코드를 변환하면서 문제가 발생했다고 유추할수 있었다.
그래서 일단 api에서 에러가 발생하는 exception에 대해 찿아보았다.
(확인해보니 이 패키지는 1.4버전부터 지원된 것이었다. ㅡ,.ㅡ;;)
확인하니 역시 정규식 패턴에 문법 에러를 나타낸다고 한다. (이건 네이놈이랑 같자나....)
그래서 패턴에 java.util.regex.Pattern을 확인해 보니
"(" , ")"을 처리할 경우에는 \\를 앞에 붙여 줘야 한다고 한다.
그래서 해당하는 함수 xssFilter()에 있는 replaceIgnoreCase()에서 "(" 과 ")"을 변화하는 부분에서 앞에 \\를 붙여 주었더니 정상적으로 동작햇다.

신경생물학, 인지과학, 학습이론 같은 분야의 최신 연구 결과를 바탕으로 만든 이 책을 읽다 보면 패턴들이 머리 속에 쉽게 들어오게 될 것이다. 이 책을 활용하면 소프트웨어 디자인 문제 해결 능력이 증대되고, 동료들과 패턴에 대해 의논할 때 구사할 수 있는 패턴 관련 용어에도 능통하게 도와줄 것이다.
목차
1. 디자인 패턴 소개
SimUDuck
조는 상속에 대해서 생각을 해 봅니다...
인터페이스는 어떨까요?
소프트웨어 개발에 있어서 바뀌지 않는 것
바뀌는 부분과 그렇지 않은 부분 분리하기
오리의 행동 디자인
Duck 코드 테스트
동적으로 행동을 지정하는 방법
캡슐화된 행동을 큰 그림으로 바라봅시다
"A는 B이다"보다"A에는 B가 있다"가 나을 수 있습니다
스트래티지 패턴
전문 용어의 위력
디자인 패턴을 어떻게 사용하나요?
디자인 도구상자
연습문제 정답
2. 옵저버 패턴
기상 모니터링 애플리케이션 개요
옵저버 패턴을 만나봅시다
출판사+구독자=옵저버 패턴
5분 드라마: 옵저버와 주제
옵저버 패턴의 정의
느슨한 결합의 위력
기상 스테이션 설계
기상 스테이션 구현
자바 내장 옵저버 패턴 사용하기
java.util.Observable의 단점
디자인 도구상자
연습문제 정답
3. 데코레이터 패턴
스타버즈에 오신 것을 환영합니다
OCP(Open-Closed Principle)
데코레이터 패턴
데코레이터를 써서 음료 주문을 완성하는 방법
데코레이터 패턴의 정의
Beverage 클래스를 장식해 봅시다
스타버즈 코드를 만들어 봅시다
데코레이터가 적용된 예: 자바 I/O
자바 I/O 데코레이터
디자인 도구상자
연습문제 정답
4. 팩토리 패턴
"new"는"구상 객체"를 뜻합니다.
객체마을 피자
객체 생성 부분을 캡슐화합시다
간단한 피자 팩토리를 만들어 봅시다
간단한 팩토리 정의
피자 가게 프레임워크
서브클래스에서 결정되는 것
PizzaStore를 만듭시다
팩토리 메소드 선언
팩토리 메소드 패턴 만나기
병렬 클래스 계층구조
팩토리 메소드 패턴의 정의
심하게 의존적인 PizzaStore
객체 의존성 살펴보기
의존성 뒤집기 원칙
그동안 피자 가게에서는...
원재료군
원재료 공장 만들기
추상 팩토리 살펴보기
무대 뒤에서
추상 팩토리 패턴 정의
팩토리 메소드 패턴과 추상 팩토리 패턴
디자인 도구상자
연습문제 정답
5. 싱글턴 패턴
유일무이한 객체
리틀 리스퍼
고전적인 싱글턴 패턴 구현법
싱글턴의 심경 고백
초콜릿 공장
싱글턴 패턴의 정의
허쉬, 문제가 생겼다
JVM이 되어 봅시다
멀티스레딩 문제 해결 방법
싱글턴 관련 Q&A
디자인 도구상자
연습문제 정답
6. 커맨드 패턴
홈 오토메이션
리모컨
클래스들을 살펴 봅시다
그동안 식당에서는...
서로 어떤 식으로 연관되는지 조금 더 자세히 봅시다
객체마을 식당 등장인물 및 그 역할
객체마을 식당과 커맨드 패턴
첫 번째 커맨드 객체
커맨드 패턴의 정의
커맨드 패턴과 리모컨
리모컨 코드
리모컨 테스트
API 문서를 만들어 봅시다...
작업취소 기능을 구현할 때 상태를 사용하는 방법
리모컨에 파티 모드를...
매크로 커맨드 사용 방법
커맨드 패턴 활용: 요청을 큐에 저장하기
커맨드 패턴 활용: 요청을 로그에 기록하기
디자인 도구상자
연습문제 정답
7. 어댑터 패턴과 퍼사드 패턴
어댑터
객체지향 어댑터
어댑터 패턴
어댑터 패턴의 정의
객체와 클래스 어댑터
오늘의 주제: 객체 어댑터와 클래스 어댑터
어댑터 실전 예제
Enumeration을 Iterator에 적응시키기
오늘의 주제: 데코레이터 패턴과 어댑터 패턴
홈 씨어터
전등, 카메라, 퍼사드!
홈 씨어터 퍼사드 구축
퍼사드 패턴의 정의
최소 지식 원칙
디자인 도구상자
연습문제 정답
8. 템플릿 메소드 패턴
커피 및 홍차 클래스 만들기
커피 및 홍차 추상화
디자인에 대해 좀더 생각해 봅시다...
prepareRecipe() 추상화
한번 정리해 봅시다...
템플릿 메소드 패턴
차를 만들어 볼까요?
템플릿 메소드로부터 무엇을 얻을 수 있었나요?
템플릿 메소드 패턴의 정의
코드 탐구
템플릿 메소드와 후크
후크 활용
한번 테스트해 볼까요?
헐리우드 원칙
헐리우드 원칙과 템플릿 메소드 패턴
야생의 템플릿 메소드
템플릿 메소드를 이용해서 정렬하기
오리를 정렬해야 합니다...
Duck 객체 대소 비교
오리 정렬 메이킹 필름
스윙 프레임
애플릿
오늘의 주제: 템플릿 메소드 패턴과 스트래티지 패턴
디자인 도구상자
연습문제 정답
9. 이터레이터와 컴포지트 패턴
객체마을 식당과 객체마을 팬케이크하우스 합병
루와 멜의 메뉴 구현법
반복을 캡슐화할 수 있을까요?
이터레이터 패턴을 만나 봅시다
DinerMenu에 Iterator를 추가합시다
디자인 살펴보기
java.util.Iterator 적용하기
한번 정리해 볼까요?
이터레이터 패턴의 정의
단일 역할 원칙
반복자와 컬렉션
자바 5에서의 반복자와 컬렉션
괜찮을 것 같았는데...
컴포지트 패턴의 정의
컴포지트 패턴을 이용한 메뉴 디자인
메뉴 구현
이터레이터
널 반복자
이터레이터 패턴과 컴포지트 패턴의 조화
디자인 도구상자
연습문제 정답
10. 스테이트 패턴
상태 구현 방법?
상태 기계의 기초
뽑기 기계 구현
이럴 줄 알았다니까요... 변경 요청 들어왔습니다.
지저분한 상태
State 인터페이스 및 클래스 정의
상태 클래스 구현
뽑기 기계 수정
스테이트 패턴의 정의
스테이트 패턴 vs. 스트래티지 패턴
정상성 점검
하마터면 그냥 넘어갈 뻔 했네요
디자인 도구상자
연습문제 정답
11. 프록시 패턴
뽑기 기계 모니터링
'원격 프록시'의 역할
RMI의 기초
뽑기 기계 원격 프록시
무대 뒤의 원격 프록시
프록시 패턴의 정의
가상 프록시
CD 커버 뷰어 가상 프록시 디자인
무대 뒤의 가상 프록시
자바 API 프록시
5분 드라마: 주 객체 보호
동적 프록시 만들기
프록시 동물원
디자인 도구상자
연습문제 정답
12. 컴파운드 패턴
컴파운드 패턴
오리와의 재회
어댑터 추가
데코레이터 추가
팩토리 추가
컴포지트 및 이터레이터 패턴 추가
옵저버 패턴 추가
패턴 정리
클래스 다이어그램
MVC 송
MVC와 디자인 패턴
패턴 안경으로 MVC 바라보기
MVC를 이용한 박자 조절
모델
뷰
컨트롤러
전략 패턴 탐색
모델 적응시키기
HeartController 준비
MVC와 웹
디자인 패턴과 모델 2
디자인 도구상자
연습문제 정답
13. 패턴과 함께 하는 행복한 삶
객체마을 가이드
디자인 패턴의 정의
디자인 패턴의 정의 - 조금 더 자세히
포스가 함께 하기를...
패턴 카탈로그
패턴을 찾는 방법
디자인 패턴 작가가 되고 싶으신가요?
디자인 패턴 분류하기
패턴으로 생각하기
패턴을 대하는 마음가짐
전문 용어의 위력을 잊지 맙시다
용어를 공유하는 다섯 가지 방법
4인방과 함께 하는 객체마을 여행
패턴을 찾아 떠나는 여행...
기타 디자인 패턴 관련 자료
패턴 동물원
사악한 안티 패턴 섬멸하기
디자인 도구상자
객체마을을 떠나며...
14. 부록: 기타 패턴
브리지 패턴
빌더 패턴
역할 사슬 패턴
플라이웨이트 패턴
인터프리터 패턴
미디에이터 패턴
메멘토 패턴
프로토타입 패턴
비지터 패턴

* 참고
- DatagramPacket : 애플리케이션에서 주고받을 데이터와 관련된 클래스 (생성자로 송신/수신기능 구분)
- DatagramSocket : 실제 데이터의 전송을 책임지는 클래스
UDPEchoServer.java
package socket.echo.udp;
import java.net.*;
import java.io.*;
public class UDPEchoServer {
//생성자
public UDPEchoServer(int port){
try{
//port를 소스로 해서 DatagramSocket 객체를 생성한다.
DatagramSocket ds = new DatagramSocket(port);
while(true){
//UDP의 실제 데이터는 일반적으로 512바이트로 제한하는 경우가 많기 때문에 바이트 배열을 크기를 512로 했다.
byte[] buffer = new byte[512];
//DatagramPacket의 생성자 중 데이터수신을 위한 생성자. 바이트배열 buffer의 길이만큼 저장한다.
DatagramPacket dp = new DatagramPacket(buffer, buffer.length);
System.out.println("ready");
//DatagramSocket객체로 수신된 Datagram을 dp에 저장한다.
ds.receive(dp);
//Datagram의 실제 데이터를 문자열로 변환한다.
String str = new String(dp.getData());
System.out.println("수신된 데이터 : "+str);
//송신을 위한 Datagram의 ip주소를 InetAddress 객체로 반환한다.
InetAddress ia = dp.getAddress();
//송신을 위한 Datagram의 포트번호를 반환한다.
port = dp.getPort();
System.out.println("client ip : "+ia+", client port : "+port);
//송신을 위한 DatagramPacket 객체를 생성한다. 이 때 IP주소와 포트번호는 수신된 Datagram의 IP주소와 포트로 해야 한다. (이 예제에서는 송신처로 그대로 보내므로 아래와 같은 형태가 된다.)
dp = new DatagramPacket(dp.getData(), dp.getData().length, ia, port);
ds.send(dp);
}
}catch(IOException e){
e.printStackTrace();
}
}
public static void main(String[] args){
new UDPEchoServer(3000);
}
}
UDPEchoClient.java
package socket.echo.udp;
import java.net.*;
import java.io.*;
public class UDPEchoClient {
private String str;
private BufferedReader file;
private static int SERVERPORT = 3000;
public UDPEchoClient(String ip, int port){
try{
//InetAddress 객체를 생성한다. 여기서는 송신할 원격지가 같기 때문에 localhost로 설정했지만, 송신할 원격지가 다르다면 원격지의 IP주소로 설정해야 한다.
InetAddress ia = InetAddress.getByName(ip);
//port를 인자로 DatagramSocket객체를 생성한다.
DatagramSocket ds = new DatagramSocket(port);
System.out.println("message : ");
file = new BufferedReader(new InputStreamReader(System.in)); //키보드로부터
str = file.readLine();
//입력받은 문자열을 바이트배열로 바꾸어 저장한다.
byte[] buffer = str.getBytes();
//송신을 위한 DatagramPacket 객체를 생성한다. 이 때 IP주소와 포트번호는 송신할 원격지의 IP주소와 포트로 해야 한다.
DatagramPacket dp = new DatagramPacket(buffer, buffer.length, ia, SERVERPORT);
//DatagramSocket 객체로 송신을 위한 Datagram을 전송한다.
ds.send(dp);
buffer = new byte[512];
//수신을 위한 DatagramPacket 객체를 생성한다.
dp = new DatagramPacket(buffer, buffer.length);
//DatagramSocket 객체로 수신된 Datagram을 dp에 저장한다.
ds.receive(dp);
System.out.println("server ip : "+dp.getAddress()+", server port : "+dp.getPort());
System.out.println("수신된 데이터 : "+new String(dp.getData()).trim());
}catch(IOException ioe){
ioe.printStackTrace();
}
}
public static void main(String[] args){
new UDPEchoClient("localhost", 2000);
}
}
- 출처 : [한빛미디어] 자바 5.0 프로그래밍 -
1. TCP 소켓 프로그램 예제의 흐름
(1) 서버 소켓 생성
(2) 서버 소켓으로 청취
(3) 클라이언트 소켓 생성
(4) (서버, 클라이언트) 소켓을 이용하여 스트림 생성
(5) 클라이언트 메시지 전송
(6) 서버 메시지 읽음
(7) 서버 메시지 전송
(8) 클라이언트 메시지 읽음
(9) (서버, 클라이언트) 소켓 종료
* 본 예제에서는 클라이언트가 메시지를 한 번만 전송할 수 있는데, 만약 클라이언트가 계속 메시지를 전송하기 위해서는 서버쪽에 스레드를 생성해야 한다.
EchoServer.java
package socket.echo;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.IOException;
import java.net.ServerSocket; //ServerSocket 클래스는 TCP서버소켓을 의미한다.
import java.net.Socket;
public class EchoServer {
private BufferedReader bufferR;
private BufferedWriter bufferW;
private InputStream is;
private OutputStream os;
private ServerSocket serverS;
public EchoServer(int port){
try{
//ServerSocket 객체를 3000번 포트를 이용하여 생성.
serverS = new ServerSocket(port);
}catch(IOException ioe){
ioe.printStackTrace();
System.exit(0);
}
while(true){
try{
System.out.println("클라이언트의 요청을 기다리는 중");
//accept() 메서드를 이용하여 클라이언트의 TCP커넥션(클라이언트에서 Socket객체를 생성하는 것)을 기다리고 있다.
//accept() 메서드는 클라이언트의 Socket객체가 생성될 때까지 블로킹 되고 있다가 클라이언트의 Socket객체가 생성되면 서버에서 클라이언트와 통신할 수 있는 Socket 객체를 리턴하게 된다.
//accept() 메서드의 유효시간이 지나면 java.net.SocketTimeoutException이 발생하는데, 이 예외가 발생하더라도 ServerSocket객체는 계속 유효하다.
//실험결과 accept() 메서드가 Socket 객체를 리턴하지 않는 한 while문의 루프도 돌아가지 않았다.
Socket tcpSocket = serverS.accept();
System.out.println("클라이언트의 IP주소 : "+tcpSocket.getInetAddress().getHostAddress());
is = tcpSocket.getInputStream(); //'소켓으로부터' 읽고
os = tcpSocket.getOutputStream(); //'소켓에' 쓴다.
bufferR = new BufferedReader(new InputStreamReader(is));
bufferW = new BufferedWriter(new OutputStreamWriter(os));
String message = bufferR.readLine();
System.out.println("수신메시지 : "+message);
message += System.getProperty("line.separator"); //엔터키넣기
bufferW.write(message);
bufferW.flush();
bufferR.close();
bufferW.close();
tcpSocket.close();
}catch(IOException ie){
ie.printStackTrace();
}
}
}
public static void main(String[] args){
new EchoServer(3000);
}
}
EchoClient.java
package socket.echo;
import java.io.*;
import java.net.*;
public class EchoClient {
private String ip;
private int port;
private String str;
BufferedReader file;
//생성자
public EchoClient(String ip, int port) throws IOException{
this.ip = ip;
this.port = port;
//Socket객체를 생성한다. Socket객체가 생성되면 서버와 TCP 커넥션이 이루어지게 된다. 동시에 서버의 accept()메서드는 클라이언트와 통신할 수 있는 Socket객체를 반환하게 된다. 따라서 클라이언트의 Socket객체와 서버의 Socket객체가 각각의 스트림을 이용하여 통신할 수 있게 된다.
Socket tcpSocket = getSocket(); //사용자 메서드
OutputStream os_socket = tcpSocket.getOutputStream(); //소켓에 쓰고
InputStream is_socket = tcpSocket.getInputStream(); //소켓에서 읽는다
BufferedWriter bufferW = new BufferedWriter(new OutputStreamWriter(os_socket));
BufferedReader bufferR = new BufferedReader(new InputStreamReader(is_socket));
System.out.print("입력 : ");
//소켓으로부터 읽는 것이 아니라 키보드로부터 읽는 또 하나의 BufferedReader
file = new BufferedReader(new InputStreamReader(System.in));
str = file.readLine();
str += System.getProperty("line.separator");
bufferW.write(str);
bufferW.flush();
str = bufferR.readLine();
System.out.println("Echo Result : "+str);
file.close();
bufferW.close();
bufferR.close();
tcpSocket.close();
}
public Socket getSocket(){ //호스트의 주소와 포트를 사용, 소켓을 만들어 리턴하는 사용자 메서드
Socket tcpSocket = null;
try{
//원격 호스트(여기서는 서버)의 주소와 포트(여기서는 멤버변수)를 사용하여 Socket객체를 생성한다.
//호스트를 찾을 수 없거나, 서버의 포트가 열려 있지 않은 경우에는 UnknownHostException 이 발생하고,
//네트워크의 실패, 또는 방화벽 때문에 서버에 접근할 수 없을 때에는 IOException 이 발생할 수 있다.
tcpSocket = new Socket(ip, port);
}catch(IOException ioe){
ioe.printStackTrace();
System.exit(0);
}
return tcpSocket;
}
public static void main(String[] args)throws IOException{
new EchoClient("localhost", 3000);
}
}
- 출처 : [한빛미디어] 자바 5.0 프로그래밍 -
1. 개요
- 서버, 클라이언트가 공유하는 '요청의 종류와 내용에 관한 프로토콜'을 만들어 로그인예제에 적용한다.
2. 로그인 예제 프로그램의 흐름
(1) 서버가 클라이언트에 로그인 요청을 한다.
(2) 클라이언트는 아이디와 패스워드를 서버에게 전송한다.
(3) 아이디와 패스워드가 정확히 맞았다는 메시지를 전송한다.
(3) 패스워드가 틀린 경우의 메시지를 전송한다.
(3) 아이디가 틀린 경우의 메시지를 전송한다.
(4) 클라이언트는 서버에게 종료 메시지를 전송한다. 이 때 서버도 프로그램을 종료한다.
3. 클래스 설명
- Protocol.java : 이 클래스는 클라이언트와 서버에서 사용하는 클래스다. 주요 목적은 packet 바이트 배열을 생성하여 프로토콜 타입과 실제 데이터(ID와 PWD)를 저장하여 packet 바이트 배열을 클라이언트와 서버가 전송하게 된다.
- LoginServer.java : 서버를 의미하며, 일반적인 서버는 클라이언트의 요청이 있는 경우 통신을 시작하는데, 이 클래스는 클라이언트가 프로그램을 시작하면 서버에서 로그인 요청을 하게 된다. 클라이언트에서 로그인 요청이 왔을 때 ID와 PWD를 체크한 후에 결과를 전송하고 클라이언트가 종료되면 프로그램도 같이 종료된다.
- LoginClient.java : 클라이언트를 의미하며, 서버에서 로그인 요청이 있는 경우 ID와 PWD를 입력하여 로그인 인증을 받게 된다. 로그인 인증의 결과와 상관없이 프로그램은 종료된다.
4. 실행
- java LoginServer
- java LoginClient 호스트주소 포트번호
Protocol.java
package socket.protocol;
import java.io.Serializable;
public class Protocol implements Serializable{
//프로토콜 타입에 관한 변수
public static final int PT_UNDEFINED = -1; //프로토콜이 지정되어 있지 않을 경우에
public static final int PT_EXIT = 0;
public static final int PT_REQ_LOGIN = 1; //로그인요청
public static final int PT_RES_LOGIN = 2; //인증요청
public static final int PT_LOGIN_RESULT = 3; //인증결과
public static final int LEN_LOGIN_ID = 20; //ID길이
public static final int LEN_LOGIN_PASSWORD = 20; //PW길이
public static final int LEN_LOGIN_RESULT = 2; //로그인인증값 길이
public static final int LEN_PROTOCOL_TYPE = 1; //프로토콜타입 길이
public static final int LEN_MAX = 1000; //최대 데이타 길이
protected int protocolType;
private byte[] packet; //프로토콜과 데이터의 저장공간이 되는 바이트배열
//생성자
public Protocol(){
this(PT_UNDEFINED);
}
//생성자
public Protocol(int protocolType){
this.protocolType = protocolType;
//어떤 상수를 생성자에 넣어 Protocol 클래스를 생성하느냐에 따라서 바이트배열 packet 의 length 가 결정된다.
getPacket(protocolType);
}
public byte[] getPacket(int protocolType){
if(packet == null){
switch(protocolType){
case PT_REQ_LOGIN : packet = new byte[LEN_PROTOCOL_TYPE]; break;
case PT_RES_LOGIN : packet = new byte[LEN_PROTOCOL_TYPE + LEN_LOGIN_ID + LEN_LOGIN_PASSWORD]; break;
case PT_UNDEFINED : packet = new byte[LEN_MAX]; break;
case PT_LOGIN_RESULT : packet = new byte[LEN_PROTOCOL_TYPE + LEN_LOGIN_RESULT]; break;
case PT_EXIT : packet = new byte[LEN_PROTOCOL_TYPE]; break;
}
}
packet[0] = (byte)protocolType; //packet 바이트배열의 첫번째 방에 프로토콜타입 상수를 셋팅해 놓는다.
return packet;
}
//로그인후 성공/실패의 결과값을 프로토콜로 부터 추출하여 문자열로 리턴
public String getLoginResult(){
//String의 다음 생성자를 사용 : String(byte[] bytes, int offset, int length)
return new String(packet, LEN_PROTOCOL_TYPE, LEN_LOGIN_RESULT).trim();
}
//String ok를 byte[] 로 만들어서 packet의 프로토콜 타입 바로 뒤에 추가한다.
public void setLoginResult(String ok){
//arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
System.arraycopy(ok.trim().getBytes(), 0, packet, LEN_PROTOCOL_TYPE, ok.trim().getBytes().length);
}
public void setProtocolType(int protocolType){
this.protocolType = protocolType;
}
public int getProtocolType(){
return protocolType;
}
public byte[] getPacket(){
return packet;
}
//Default 생성자로 생성한 후 Protocol 클래스의 packet 데이타를 바꾸기 위한 메서드
public void setPacket(int pt, byte[] buf){
packet = null;
packet = getPacket(pt);
protocolType = pt;
System.arraycopy(buf, 0, packet, 0, packet.length);
}
public String getId(){
//String(byte[] bytes, int offset, int length)
return new String(packet, LEN_PROTOCOL_TYPE, LEN_LOGIN_ID).trim();
}
//byte[] packet 에 String ID를 byte[]로 만들어 프로토콜 타입 바로 뒷부분에 추가한다.
public void setId(String id){
System.arraycopy(id.trim().getBytes(), 0, packet, LEN_PROTOCOL_TYPE, id.trim().getBytes().length);
}
public String getPassword(){
//구성으로 보아 패스워드는 byte[] 에서 로그인 아이디 바로 뒷부분에 들어가는 듯 하다.
return new String(packet, LEN_PROTOCOL_TYPE + LEN_LOGIN_ID, LEN_LOGIN_PASSWORD).trim();
}
public void setPassword(String password){
System.arraycopy(password.trim().getBytes(), 0, packet, LEN_PROTOCOL_TYPE+LEN_LOGIN_ID, password.trim().getBytes().length);
packet[LEN_PROTOCOL_TYPE + LEN_LOGIN_ID + password.trim().getBytes().length] = '\0';
}
}
LoginServer.java
package socket.protocol;
import java.net.*;
import java.io.*;
public class LoginServer {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
ServerSocket sSocket = new ServerSocket(3000);
System.out.println("클라이언트 접속 대기중 ...");
Socket socket = sSocket.accept();
System.out.println("클라이언트
접속");
//어차피 바이트배열로 전송할 것이기 때문에 필터스트림 없이 Input/OutputStream만 사용해도 된다.
OutputStream os = socket.getOutputStream();
InputStream is = socket.getInputStream();
//로그인정보 요청용 프로토콜 객체 생성
Protocol protocol = new Protocol(Protocol.PT_REQ_LOGIN);
//로그인정보 요청 패킷을 전송
os.write(protocol.getPacket());
while(true){
//새 Protocol 객체 생성 (기본 생성자)
protocol = new Protocol();
//기본 생성자로 생성할 때에는 바이트배열의 길이가 1000으로 지정됨
byte[] buf = protocol.getPacket();
//socket으로부터 읽어서(클라이언트의 입력) buf 에 저장한다. (블로킹메서드)
is.read(buf);
//패킷 타입을 얻고 Protocol 객체의 packet 멤버변수에 buf를 복사한다.
int packetType = buf[0];
protocol.setPacket(packetType, buf);
if(packetType == Protocol.PT_EXIT){
protocol = new Protocol(Protocol.PT_EXIT);
os.write(protocol.getPacket());
System.out.println("서버종료");
break;
}
switch(packetType){
//클라이언트가 로그인 정보 응답 패킷인 경우 (클라이언트의 로그인 정보 전송일 경우)
case Protocol.PT_RES_LOGIN :
System.out.println("클라이언트가 로그인 정보를 보냈습니다.");
String id = protocol.getId();
String password = protocol.getPassword();
System.out.println(id+"@@"+password+"@@");
if(id.equals("bruce")){
if(password.equals("1111")){
//로그인 성공
protocol = new Protocol(Protocol.PT_LOGIN_RESULT);
protocol.setLoginResult("1");
System.out.println("로그인 성공");
}else{
//암호 틀림
protocol = new Protocol(Protocol.PT_LOGIN_RESULT);
protocol.setLoginResult("2");
System.out.println("암호 틀림");
}
}else{
//아이디 존재 안함
protocol = new Protocol(Protocol.PT_LOGIN_RESULT);
protocol.setLoginResult("3");
System.out.println("아이디 존재 안함");
}
System.out.println("로그인 처리 결과 전송");
os.write(protocol.getPacket()); //socket의 OutputStream 에 기록한다.
break;
}//end switch
}//end while
is.close();
os.close();
socket.close();
}
}
LoginClient.java
package socket.protocol;
import java.net.*;
import java.io.*;
public class LoginClient {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
if(args.length <2)System.out.println("사용법 : java LoginClient 호스트주소 포트번호");
Socket socket = new Socket(args[0], Integer.parseInt(args[1]));
OutputStream os = socket.getOutputStream();
InputStream is = socket.getInputStream();
Protocol protocol = new Protocol();
byte[] buf = protocol.getPacket();
//while문을 사용하는 이유 : InputStream 으로부터 계속 읽어들이기 위해서...?
while(true){
//소켓의 InputStream 으로부터 읽어들여서 바이트배열 buf에 저장한다. (서버로부터 온 값)
is.read(buf);
int packetType = buf[0];
protocol.setPacket(packetType, buf);
if(packetType == Protocol.PT_EXIT){
System.out.println("클라이언트 종료");
break;
}
switch(packetType){
case Protocol.PT_REQ_LOGIN :
System.out.println("서버가 로그인정보 요청");
BufferedReader userIn = new BufferedReader(new InputStreamReader(System.in));
System.out.print("아이디 : ");
String id = userIn.readLine();
System.out.print("암호 : ");
String pwd = userIn.readLine();
//서버로 패킷 전송 (로그인 정보 전송)
protocol = new Protocol(Protocol.PT_RES_LOGIN);
protocol.setId(id);
protocol.setPassword(pwd);
System.out.println("로그인 정보 전송");
os.write(protocol.getPacket());
break;
case Protocol.PT_LOGIN_RESULT :
System.out.println("서버가 로그인 결과 전송");
String result = protocol.getLoginResult();
if(result.equals("1")){
System.out.println("로그인 성공");
}else if(result.equals("2")){
System.out.println("암호 틀림");
}else if(result.equals("3")){
System.out.println("존재하지 않는 아이디");
}
protocol = new Protocol(Protocol.PT_EXIT);
System.out.println("종료패킷 전송");
break;
}
}//end while
os.close();
is.close();
socket.close();
}
}
- 출처 : [한빛미디어] 자바 5.0 프로그래밍 -
|
가볍고 쉬운 Ajax - jQuery 시작하기
2007/06/10 11:45
|
시작 하기 전에
jQuery는 2006년 초에 John Resig가 개발한 자바스크립트 라이브러리 이다. 전체 라이브러리가 55kb밖에는 안되는 초 경량이면서도 누구나 쉽게 브라우져 기반의 자바스크립트 프로그래밍을 쉽게 할 수 있을 뿐더러, Ajax또한 쉽게 구현 할 수 가 있다. 또한 플러그인 방식의 확장을 지원하여, 현재 많은 수의 플러그인을 확보하고 있다.
나온지는 얼마 안되었지만 수백여개의 사이트가 사용할 만큼 안정적이며, 유명한 라이브러리 이다. 구지 비교하자면 prototype이라는 기존 유명 라이브러리와 비교가 가능하겠지만, 더욱 간단하며, 쉽다는것을 장점으로 꼽고 있다.(사실 본인은 prototype을 잘 모른다. 따라서 기존 개발자들의 의견을 빌린것이다. 어느것이 더 좋다는 표현이 아님을 알아달라)
무엇이 짧은 시간안에 jQuery를 유명하게 하였을까? 이런 호기심을 가지고 깊이 살펴본 결과 그 이유를 알 수 있었다. 작고, 쉽고, 그러나 강력하다는 것이 그 이유이다. 따라서 이런 본인의 경험을 공유하고자 이글을 올린다.
이 글은 jQuery의 튜토리얼문서를 기반으로하여 작성 되었다. 따라서 예제의 상당 부분은 동일하다, 단, 직접 프로그래밍을 통해 소스를 돌려보고 그 경험을 글로 올리는것이니 만큼 그냥 번역 보다는 더 나을 것으로 판단 한다.
참고로 이글에서 Ajax는 비동기 통신의 경우에만 국한 하겠다. 그 이유는 jQuery에서 Ajax라는 별도 네임스페이스로 라이브러리를 지원하기 때문이다.
자바스크립트 전용 IDE 소개 - Aptana
프로그래머들 중에는 IDE를 싫어하는 사람도 있다. 그러나 나는 없는것보다는 있는것이 더 낳다고 생각한다. 특히 한 언어를 위한 전용 환경을 지원할 경우는 더욱 그러하다. 브라우져 기반의 자바스크립트 프로그래밍을 하다보면 가장 어려운 점이 디버깅이다. printf디버거도 어려울 경우가 많다.(printf디버거는 디버깅을 위해 필요한 값을 출력하여 확인 하는 방법을 말한다.-본인이 만들어낸 용어이다.) 특히 브라우져의 경우는 로컬파일을 사용할 수 없어 화면을 이용한 값의 출력에 의존하여야 함으로 루프값을 출력할 경우는 거의 죽음이고, HTML태그를 생성하여 이곳에 이벤트를 결합하고, 코딩하는것을 반복하는 동적 HTML프로그래밍은 더욱 디버깅이 어렵다. 따라서 브라우져의 플러그인과 결합된 디버거를 사용하는것이 매우 도움이 된다.
Firefox용 Firebug가 대표적인 것인데, 가장 많이 사용하는 디버거 이기도 하다. 그러나 편집기와 독립된 형태로 사용해야 함으로 수정 작업 시 불편함이 따른다. 이러한 점을 개선하려면 역시 디버거와 편집기를 포함하는 전용 IDE가 필요하다.
한가지더 이야기 하면, 기존 Eclipse와 같은 IDE에서 지원하는 Code Inspector기능의 필요를 들 수 있다. 사실 한 언어에 익숙한 사람이면 이 기능이 불편 하다. 매번 객체명뒤 점을 찍어 객체의 맴버를 보는 것은 그것을 아는 사람에게는 편집속도만 떨어뜨릴 뿐이다. 그러나 언어에 익숙치 않다거나, 남이 제공한 라이브러리를 사용할 경우는 이기능이 매우 유용하다. 특히 해당 맴버의 간단한 도움말까지 표시되면 API문서를 일일이 그때마다 검색하지 않아도 되어서 편리하다.
기존 자바 스크립트 편집기는 사실 이러한 기능이 부족한것이 사실 이었다. 그러나 지금 소개할 Aptana는 자바스크립트 전용 IDE를 표방한 몇 안되는 IDE중 하나이다. 이클립스 기반에 프러그인으로 개발되고 배포는 리치클라이언트와 플러그인 방식 모두를 지원한다. 따라서 기존 설치된 이클립스에서도 사용할 수 있고, 별도 설치를 통해 독립적인 IDE로 사용 할수도 있다. 다음은 Aptana의 실행 화면이다.
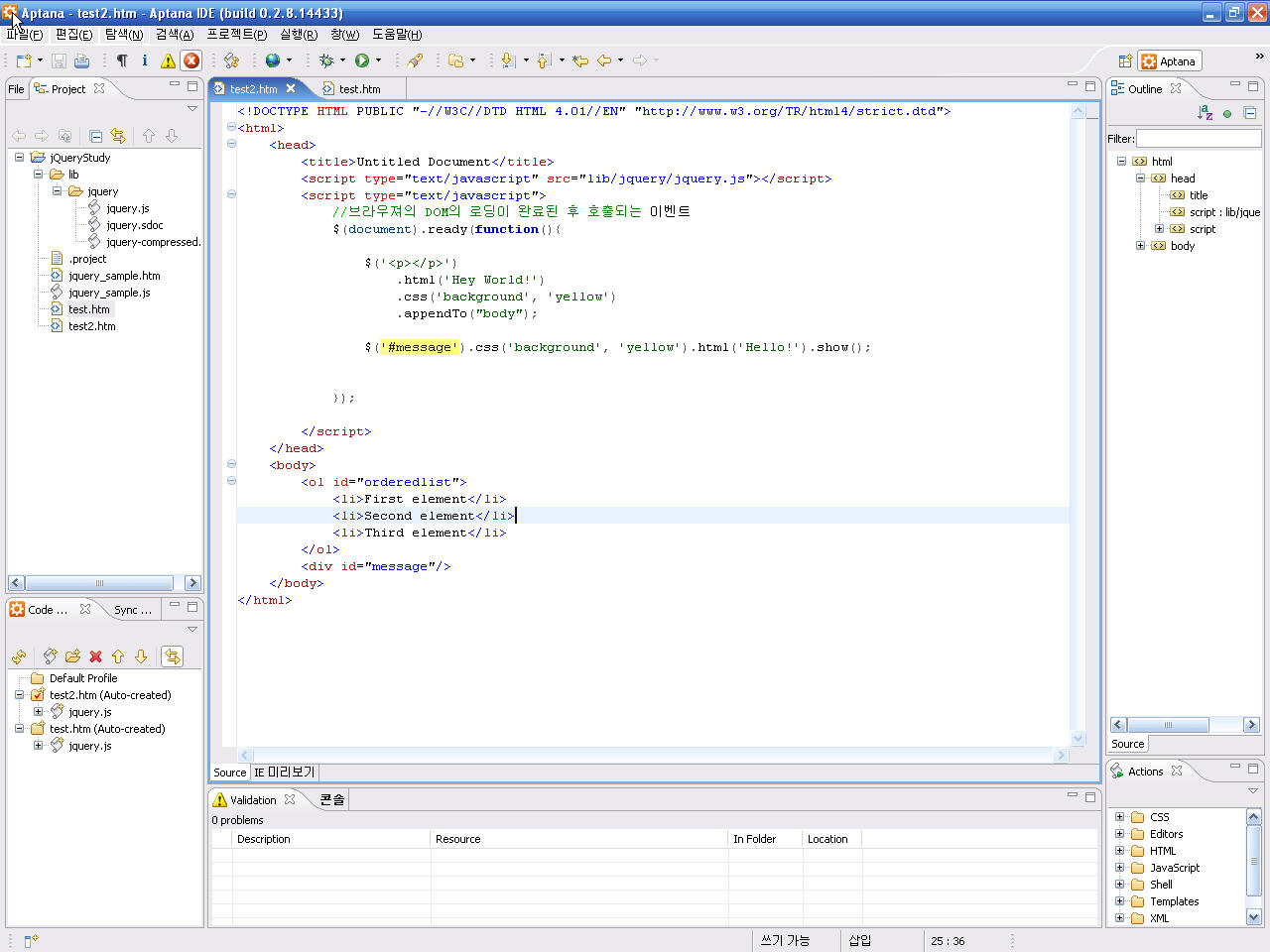
특히 Code Inspector가 매력 적이다. 노란 색으로 나오는 도움말도 매우 유용하다.
Apatana의 설치는 쉽다. 또한 무료로 사용 할 수 가 있다. (http://www.aptana.org/)
사용법은 기존 Eclipse와 동일하다. 단 디버거를 사용하려면 Firefox가 설치 되어 있어야 한다.
또한 기존 Ajax라이브러리들도 지원하는데, jQuery도 지원한다. 위 화면에서 객체의 도움말이 나올 수 있는것은 이 때문이다. 프로젝트 생성 시 jQuery프로젝트를 선택하여 생성 하면 된다.
jQuery 사용
위에서 소개한 Aptana를 설치 하였다면, 별도 jQuery설치는 필요 없다. 하지만 설치가 어려운것은 아니다. jQuery라이브러리는 55kb짜리 파일 하나로 되어 있다. 이를 HTML에 사용 선언을 하여 주면 된다.
<html>
<head>
<script type="text/javascript" src="path/jquery.js"></script>
<script type="text/javascript">
// Your code goes here
</script>
</head>
<body>
<a href="http://jquery.com/">jQuery</a>
</body>
</html>
기존 자바 스크립트 라이브러리 사용과 차이가 없다. 단, 압축버젼과 그렇지 않은 버젼 두개의 파일을 제공하는데, 프로그래밍을 할 때는 디버깅을 위해 압축하지 않은 버젼의 파일을 사용하고, 배포할 경우 압축된 버젼을 사용하는 것이 좋다.
jQuery 의 시작 이벤트
보통의 자바스크립트 프로그래머들은 브라우져의 document가 모두 다운로드 되어진 상태에서 코드를 시작하기위해 다음과 같은 이벤트에 스크립트 코드를 넣는다.
window.onload = function(){ ... }
그러나 이 경우 이미지 까지 다운로드가 모두 완료 된 후 이벤트가 호출되기 때문에, 큰이미지의 경우 실행속도가 늦은 것처럼 사용자에게 보일 수 있다. 따라서 jQuery는 이러한 문제를 해결하기위해 다음과 같은 이벤트를 제공한다.
$(document).ready(function(){
// 이곳에 코드를 넣으면 된다.
});
이 이벤트는 브라우져의 document(DOM)객체가 준비가 되면 호출이 된다. 따라서 이미지 다운로드에 의한 지연이 없다.
위 코드는 다음과 같이 생략하여 사용 가능하다.
$(function() { // run this when the HTML is done downloading });
사용자 이벤트 처리 - 클릭이벤트의 예
특정 태그를 클릭 했을경우 이벤트의 처리를 jQuery에서 어떻게 처리 하는지를 살펴 보자. 다음은 위 HTML예제의 앵커(a)태그 클릭 시 이벤트를 처리하는 코드 이다.
$("a").click(function(){
alert("Thanks for visiting!");
});
jQuery에서 이벤트 처리는 콜백함수를 통해 수행된다. 이코드는 HTML에 있는 모든 앵커 태그의 클릭 시 팦업창을 통해 메시지를 출력해 준다.
코드를 보면 $()로된 문법을 볼 수 있을 것이다. 이것은 jQuery의 셀렉터 이다. $("a")가 의미하는 것은 HTML(브라우져의 DOM)에서 앵커태그 모두를 의미한다. 이후 .click()메소드는 이벤트 메소드로서 이곳에 콜백함수를 파라메타로 넣어 이벤트 처리를 수행 하는것이다. 함수는 위에서 처럼 익명(function(){...})이나 선언된 함수 모두를 사용할 수 있다.
jQuery의 셀렉터
$()로 시작하는 셀렉터를 좀더 살펴보자. jQuery는 HTML, DOM객체등을 CSS나 XPATH의 쿼리방법과 동일한 방법으로 선택 한다. 앞선 예처럼 문자열로 특정 태그를 선택하는 것은 CSS를 작성해 본 프로그래머라면 익숙할 것이다. 이와 같은 방법 외에도 다음과 같이 태그의 id를 통해 선택 할 수 있다.
$(document).ready(function() {
$("#orderedlist").addClass("red");
});
위 코드는 id가 orderedlist인 태그에 red라는 CSS 클래스를 할당하는 코드 이다. 만약 이태그가 하위 태그를 가지고 있다면 다음과 같이 선택 할 수 있다.
$(document).ready(function() {
$("#orderedlist > li").addClass("blue");
});
이코드는 id가 orderedlist인 태그의 하위 태그 중 <li> 태그 모두에 blue라는 CSS 클래스를 할당하는 코드 이다. 이코드는 jQuery메소드를 이용 다음과 같이 바꾸어 사용 할 수도 있다.
$(document).ready(function() {
$("#orderedlist").find("li").each(function(i) {
$(this).addClass("blue");
});
});
한가지 다른 점은 모든 태그에 동일하게 CSS 클래스를 적용하는 방식이 아닌 개별 태그를 선택하여 적용할 수 있다는 것이다.
XPath를 사용하는 예를 다음과 같은 것을 들 수 있다
//절대 경로를 사용하는 경우
$("/html/body//p")
$("/*/body//p")
$("//p/../div")
//상대경로를 사용하는 경우
$("a",this)
$("p/a",this)
다음과 같이 두 방식을 혼용하여 사용 할 수도 있다.
//HTML내 모든 <p>태그중 클래스속성이 foo인 것 중 내부에 <a> 태그를 가지고 있는것
$("p.foo[a]");
//모든 <li>태그 중 Register라는 택스트가 들어있는 <a> 태그
$("li[a:contains('Register')]");
//모든 <input>태그 중 name속성이 bar인 것의 값
$("input[@name=bar]").val();
이외에도 jQuery는 CSS 3.0 표준을 따르고 있어 기존 보다 더많은 쿼리 방법을 지원하고 있다. 자세한것은 jQuery의 API 설명을 참고 하라(http://docs.jquery.com/Selectors)
Chainability
jQuery는 코드의 양을 줄이기 위해 특별한 기능을 제공한다. 다음 코드를 보자
$("a").addClass("test").show().html("foo");
<a>태그에 test라는 CSS 클래스를 할당한다. 그후 태그를 보이면서 그안에 foo라는 텍스트를 넣는다. 이런 문법이 가능한 이유는 $(), addClass(), show()함수 모두가 <a>태그에 해당하는 객체를 결과로 리턴해주면 된다. 이를 Chainability라 한다. 좀더 복잡한 경우를 보자
$("a")
.filter(".clickme")
.click(function(){
alert("You are now leaving the site.");
})
.end()
.filter(".hideme")
.click(function(){
$(this).hide();
return false;
})
.end();
// 대상 HTML이다
<a href="http://google.com/" class="clickme">I give a message when you leave</a>
<a href="http://yahoo.com/" class="hideme">Click me to hide!</a>
<a href="http://microsoft.com/">I'm a normal link</a>
중간에 end()함수는 filter()함수로 선택된 객체를 체인에서 끝는 역할을 한다. 위에서는 clickme클래스의 <a>태그 객체를 끊고 hideme를 선택하는 예이다. 또한 this는 선택된 태그 객체를 말한다.
이런 Chainability를 지원 하는 jQuery메소드들에는 다음과 같은 것들이 있다.
- add()
- children()
- eq()
- filter()
- gt()
- lt()
- next()
- not()
- parent()
- parents()
- sibling()
Callbacks
위에서 click()이벤트를 콜백함수를 통해처리하는 코드를 살펴 보았다. 콜백함수는 기존 자바나 .NET의 그것과 같다. 다음 코드를 보자
$.get('myhtmlpage.html', myCallBack);
먼저 $.get()은 서버로 부터 HTML(또는 HTML 조각)을 가져오는 함수 이다. 여기서 myCallBack함수는 전송이 완료 되면 호출되는 콜백 함수 이다. 물론 앞선 예의
click()이벤트 콜백처럼 익명함수 function(){}을 사용 해도 된다. 그러나 이와 같이 미리 선언된 함수를 콜백으로 사용할 경우 파라메타의 전달 방법은 좀 다르다. 흔히 다음과 같이 하면 될것이라 생각할 것이다.
$.get('myhtmlpage.html', myCallBack(param1, param2));
그러나 위와 같은것은 자바스크립트의 클로져(closure)사용에 위배가 된다. 클로져는 변수화 될수 있는 코드 블록을 이야기한다. 즉 스트링변수와 같이 파라메타로 전달될 수 있지만, 실행가능한 함수 인 것이다. 일반적으로 함수를 ()제외하고 이름만을 사용하면 클로져가 된다. 위의경우 $get()함수의 파라메타로 전달된 myCallBack함수는 클로져로 전달된것이 아닌 myCallBack()를 실행한 결과 값이 전달 된다. 따라서 다음과 같이 코드를 작성하여야 한다.
$.get('myhtmlpage.html', function(){
myCallBack(param1, param2);
});
만약 선언된 함수가 아닌 익명함수를 콜백으로 사용할경우는 다음과 같이 하면 된다.
$.get('myhtmlpage.html', function(param1, param2){
//이곳에 코드를 넣는다.
});
jQuery 의 애니메이션
HTML의 태그를 사라지고 나타내게 하거나, 늘리고 줄이고, 이동시키는 애니매이션 동작은 많이 사용하는 기는 중 하나이다. jQuery는 다양안 애니메이션 기능을 메소드를 통해 제공한다. 다음 코드를 보자
$(document).ready(function(){
$("a").toggle(function(){
$(".stuff").hide('slow');
},function(){
$(".stuff").show('fast');
});
});
이코드는 <a>태그중 stuff클래스가 할당된것을 토글로 느리게 감추고, 빨리 보이게 하는 함수 이다.
다음은 animate()메소드를 이용하여 여러 애니메이션을 합쳐 실행하는 예이다.
$(document).ready(function(){
$("a").toggle(function(){
$(".stuff").animate({ height: 'hide', opacity: 'hide' }, 'slow');
},function(){
$(".stuff").animate({ height: 'show', opacity: 'show' }, 'slow');
});
});
위 코드는 높이와 투명도를 동시에 천천히 사라지고, 나타나게 하는 코드 이다.
jQuery에서의 Ajax
Ajax는 서버와의 비동기 통신을 말한다. 일반적으로 Ajax하면 요즘은 자바스크립트를 이용한 브라우져의 동적 DOM의 처리, 즉 DHTML, CSS등을 포함하지만, jQuery에서는 Ajax라는 네임스페이스를 통해 비동기 서버 통신을 하는것을 말한다.먼저 다음 예를 보자
$.ajax({
type: "GET",
url: "test.js",
dataType: "script"
})
이 예는 GET방식으로 서버에서 자바스크립트를 로딩하고 실행하는 코드 이다.
다음 예를 보자
$.ajax({
type: "POST",
url: "some.php",
data: "name=John&location=Boston",
success: function(msg){
alert( "Data Saved: " + msg );
}
});
이는 서버로 부터 POST방식으로 파라메터를 주어 데이터를 가져온 후 이를 success콜백을 이용해 처리하는 코드이다. 아마 Ajax에서 가장 많이 사용하는 코드일 것이다. success말고도 $.ajax()함수는 다양한 옵션을 제공한다. 자세한 내용은 API설명을 참조하라 (http://docs.jquery.com/Ajax)
다음 예는 이 옵션 중 async(비동기)방식을 사용할지 아닐지를 사용한 코드이다.
var html = $.ajax({
url: "some.php",
async: false
}).responseText;
맺으며...
지금까지 jQuery에 대해 간단히 살펴 보았다. 혹자는 Dojo나 Extjs와 같이 버튼, 그리드등의 위젯이 지원되지 않는다고 실망할 것이다.그러나 jQuery는 Plugin을 지원한다. 이중 Interface와 같은 플러그인은 그 완성도가 매우 높다. 이것 말고도 수백개의 플러그인들이 홈페이지를 통해 공개 되어 있다.(http://docs.jquery.com/Plugins)
하지만 내 경험상으로 그리드와 같은 복잡한 위젯이 아니더라도 자바스크립크를 이용한 동적인 홈페이지와 Ajax를 통한 비통기 통신만으로도 대부분의 고객 요구와 문제를 해결 할 수 있다. 실제로 jQuery는 MSNBC와 같은 유명한 많은 사이트에서 사용되고 있다.(http://docs.jquery.com/Sites_Using_jQuery)
따라서 어떤 서비스를 제공하느냐에 따라 필요한 위젯을 플러그인을 사용하거나 직접 개발하여 사용하는것이 더 나은 전략이라 생각한다. 사실 미리 만들어진 위젯도 나에게 맞추어 사용하기 위해서는 그래픽, CSS등 많은 부분을 손 대야 한다. 차라리 기본 원리를 알고 이를 확장하는 것이 좀더 전문적이고 어려운 문제를 해결 할 수 있는 길이라 생각 한다.
시간이 허락 한다면 꾸준히 jQuery의 개발 경험을 공유 하고 싶은 마음 이다.
[출처] 가볍고 쉬운 Ajax - jQuery 시작하기|작성자 하루살이
jQuery/Core란?
jQuery/Core란 jQuery의 핵심이 되는 것을 의미한다. 그만큼 우리가 jQuery를 사용할 때 많이 사용되는 부분이기도 하다.
하지만 Core라고해서 어려울것은 없고, 의외로 간단하다. Core를 표현하면 "$()"이렇게 된다.
참고로,
jQuery를 표현할 때 두가지가 있는데 한가지는 "jQuery(document).ready()" 이렇게 "jQuery"를 사용하는 방법과 "$(document).ready()" 처럼 "$"로 사용하는 방법이 있다. 이것은 사용자 취향에 맞게 선택해서 사용하면 된다.
정확한 개념을 알고 싶으신 분은 http://docs.jquery.com/Core 여기로 가시면 자세히 알 수가 있다. 하지만 저 처럼 영어에
약하신 분들은 이렇게 이해를 하시면 된다.
그럼 이제 사용법에 대해서 한번 살펴 봅시다.
jQuery 사용법
여기서 사용되는 예제나 API는 http://docs.jquery.com/ jQuery공식 사이트에서 발췌한 것임을 미리 말씀드리고 시작합니다.
1. jQuery( expression, context )
: expression는 String로 표현되고 특정 태그를 찾을때 사용되며, context는 Element나 jQuery으로 인자 값으로 받는다.
즉, $("input:radio", document.forms[0]); 이와 같이 사용된다.
2. jQuery( html )
: jQuery는 인자값으로 html 태그를 받아 그 태그를 HTML페이지에 추가를 할 수가 있다.
즉, 이렇게 $("<div><p>Hello</p></div>").appendTo("body") 사용이 되기도 하고, $("<input/>").attr("type", "checkbox");
이렇게도 사용되기도 한다.
풀이 하자면 첫 번째는 "body"안에 "<div><p>Hello</p></div>"를 삽입(appendTo()는 특정 태그에 사입할 때 사용 )한다는
애기고 두번째는 "input"를 생성하되 "type=checkbox"로 하여 태그를 생성하게 된다. 두번째는 HTML 마지막 부분에 삽입이
된다.
3. jQuery( elements )
: DOM element(s) 를 인자로 받아 그 지역의 elements를 설정할 수가 있다.(한개 혹은 다수를 지정할 수가 있다.)
$(document.body).css( "background", "black" ); -> HTML 배경색을 검정색으로 바꾼다.
$(myForm.elements).hide() -> myForm의 이름을 가진 form안의 elements을 숨긴다.
4. jQuery( callback )
: 이것은 인자값을 함수로 지정을 할 수가 있다는 애기로 jQuery를 처음 시작하는 부분에서 많이 접해 봤을 것이다.
즉, "$(document).ready(function(){....};)" 이 부분
이렇게 사용하는 것은 특정 이벤트가 발생할 때 그 부분을 함수로 처리 하기 위해서 이다. 예를 들어 마우스를 클릭시
경고창을 띄워주고 싶다면 아래와 같이 하면 된다.
"$(document).click(function(){
alert("마우스가 눌려짐!!");
};)"
- jQuery Object Accessors
이번에는 직접 오브젝트를 엑세스할 수 있는 jQuery에 대해서 알아 본다. 뭐, jQuery 홈페이지에 가면 다 나와 있는 것들이긴 하지만 그래도 본좌의 나름 해석판을 듣고 싶다면 계속 봐도 된다. 다만, 본좌도 영어가 짧기 때문에 직접 실행해 봐서 이해 하기도 한 부분도 있고 이리저리 찾아 다니면서 알아낸 것 들도 있다. 그래서 영어 잘하시는 분 들이 봤을 경우 영 아니다 싶으면 자세히 답변을 남겨 주시면 참고하여 수정토록 하겠음...
그럼 오브젝트를 엑세스 할 수 있는 jQuery 에 대해서 알아 봅시다.
1. each( callback )
: 해당 오브젝트에서 어떤 함수처리를 하고 싶을 경우 사용된다. 코드를 직접 보면 이해가 쉽게 된다.
$(document.body).click(function() {
$("div").each(function (i) {
// 클릭 이벤트가 발생 되었을 경우 "div"태그에서만 글 색상을 변경하도록 한다.
if (this.style.color != "blue") {
this.style.color = "blue";
} else {
this.style.color = "";
}
});
});
이 코드를 실행 시키면 클릭 할때마다 색깔이 변경이 된다. 참고로 이 코드는 "body"안의 모든"div"태그를 뜻한다. 특정 "div"
에서만 이벤트가 발생되기를 원하시면 그 태그의 인덱스를 찾아야 할 것이다.
2. size()
: 해당 오브젝트의 Elements의 수를 알고자 할 때 사용된다.
$(document.body).click(function () {
$(document.body).append($("<div>"));
var n = $("div").size();
$("span").text("There are " + n + " divs." +
"Click to add more.");
}).click(); // trigger the click to start
3. length()
: 해당 오브젝트의 Elements의 수를 알고자 할 때 사용된다. size()와 동일하다.
$(document.body).click(function () {
$(document.body).append($("<div>"));
var n = $("div").length;
$("span").text("There are " + n + " divs." +
"Click to add more.");
}).trigger('click'); // trigger the click to start
4. eq( position )
: 해당 포지션에 위차한 태그를 찾는다. 한마디로 아파트로 비교하자면 몇호실을 찾는지와 같다. "405호실를 청소해라!"라는
명령이 있다면 그 아파트의 "405호실"을 찾아가서 거기만 청소를 하면 된다. 구지 다른곳도 청소할 필요가 없다는 것이다.
position의 위치는 0 부터 시작해서 -1까지다.
$("p").eq(1).css("color", "red"); // "p"태그에서 1(0 부터 시작하므로 두번째를 의미한다.)번지에 해당하는 "p"를 변경한다.
5. get()
: 해당 태그의 Elements 들을 Array형태로 리턴한다. 즉, '$("div").get() 하면 모든 div태그 들을 Array 형태로 리턴한다.'
한마디로 하면 DOM의 Elements를 배열로 리턴하는 것이다.
function disp(divs) {
var a = [];
for (var i = 0; i < divs.length; i++) {
a.push(divs[i].innerHTML);
}
$("span").text(a.join(" "));
}
disp( $("div").get().reverse() ); // div태그의 값들을 읽어 와서 그 값의 순서를 뒤집는다.
// 예를 들어
// <div>1</div><div>2</div><div>3</div> 이 있으면 reverse() 하면 3, 2, 1로 순서가 뒤집히게 된다.
6. get( index )
: index에 해당되는 위치의 element을 가져온다. 즉, 단일 element를 가져 오게 되는 것이다.
$("*", document.body).click(function (e) { // body안의 모든 Elements에서 클릭 이벤트가 발생되면.
e.stopPropagation();
var domEl = $(this).get(0); // 클릭된 태그의 Elements중 0번지에 해당하는 Element를 가져온다.
$("span:first").text("Clicked on - " + domEl.tagName); // 0번지의 태그이름을 출력한다.
});
이해하는데에는 어렵지 않을 것이다. 프로그래밍을 하다보면 위와 비슷한 함수를 많이 접해 보기 때문이다.
7. index( subject )
: subject의 인덱스 번호를 찾는다. 인덱스 번호도 0부터 시작된다.
$("div").click(function () {
// this is the dom element clicked
var index = $("div").index(this); // "div"태그에서 클릭이벤트가 발생 될경우 그 "div"태그의 인덱스 찾아서 리턴한다.
$("span").text("That was div index #" + index);
});
jQuery/Core에 대해서는 여기서 마무를 하겠다. 이 외에도 Data Cash, Plugins에 대한 것도 있지만 아직은 다루지 않겠다.
시간이 짬짬이 날때 마다 글을 남기곤 있지만 회사 일도 바쁘다 보니 쉽게 글을 쓰지 못하는 것도 없지 않아 있다.
이 글을 쓰면서 예제 코드도 함께 올리려고 했는데 너무 도둑놈이 되는것 같아서 간단하게만 소개만 하였다. 뭐 본좌 나름대로
예제소스를 만들어 올리면 되지만...... 그렇게 하려면 시간이 많이 소모가 되고.... 잘못하다가는 회사에서 짤릴까봐 안했음..^^
다음은 Selector에 대해서 알아 볼 것이다. 나의 허접강의는 계속 된다..쭈욱~~~ ^^b
jQuery 란?
jQuery는 자바스크립트와 HTML 사이의 상호 작용을 강조하는 경량화된 웹 애플리케이션 프레임워크이다.
존 레시그에 의해, 2006년 뉴욕 시 바캠프(Barcamp NYC)에서 릴리즈되었다
jQuery는 MIT 라이선스와 GNU 일반 공중 사용 허가서의 듀얼 라이선스 하의 자유 오픈 소프트웨어이다.
기능
jQuery는 다음과 같은 기능을 갖고 있다.
- DOM 엘리먼트 선택
- DOM 트래버설 및 수정 (CSS 1-3지원. 기본적인 XPath를 플러그인 형태로 지원)
- 이벤트
- CSS 조작
- 특수효과 및 애니메이션
- Ajax
- 확장성
- 유틸리티 - 브라우저 버전, "each"함수
- 자바스크립트 플러그인
사용법
jQuery는 한 개의 JavaScript파일로 존재한다. 공통의 DOM, 이벤트, 특수효과, Ajax함수를 포함한다. 다음 코드를 쓰면,
웸 페이지로 포함시킬 수 있다.
<script type="text/javascript" src="path/to/jQuery.js"></script>
jQuery는 두 가지의 상호 작용 스타일을 갖고 있다.
- $함수 이용 . jQuery 오브젝트의 팩토리 메소드이다. 이 함수들은 "chainable"하다: 각각은 jQeury 오브젝트를 리턴한다.
- $. - 가 붙은 함수 이용. 이들 함수는 jQuery 오브젝트 그 자체와 연동되지는 않는다.
일반적으로 여러 개의 DOM노드들을 조작하는 웍플로우는 $함수로 시작된다. CSS 셀렉터 스트링을 가지고 호출된다. 결과적으로
0개 혹은 그 이상을 HTML 페이지 내의 엘리먼트를 리퍼런스하는 jQuery 오브젝트가 리턴된다. 이 노드 집합들은 jQuery 오브젝트에
대해 인스턴스 메소드 들을 적용함으로써 조작될 수 있다. 혹은 노드들 그 자체가 조작될 수 있다. 예를 들면 다음과 같다.
$("div.test").add("p.quote").addClass("blue").slideDown("slow");
.. div 태그가 달리 모든 엘리먼트를 찾되, 클래스 애티르뷰가 test인 것을 찾는다. <p>태그를 찾되, 클래스 애트리뷰트가
quote인 것을 찾는다. 찾아낸 각각의 엘리먼트에 대해 클래스 애트리뷰트 blue를 추가한다. 그 뒤 애니메이션 효과를 주어 아래쪽으로
슬라이드(미끄러지게) 시킨다. $및 add함수는 찾아낸(matched) 집합(set)에 영향을 준다. addClass및 slideDown는 리퍼런스된
노드들에 영향을 준다.
$.가 앞에 붙은 함수들은, 글로벌 프로퍼티나 비해이비어에 영향을 주는, 간편한(유틸리티)메소드들이다. 예를 드면 다음과 같다.
$.each([1,2,3], function() {
document.write(this + 1);
});
... 234를 도류먼트에 출력한다.
Ajax 루틴들은 $.ajax및 관련 코드를 이용하여 수행할 수 있다. 이를 사용하여, 원격 데이터(remote data)를 로드하거나 조작할 수 있다.
$.ajax({
type: "POST",url: "some.php",
data: "name=John&location=Boston",
success: function(msg){
alert( "Data Saved: " + msg );
}
});
파라미터 name=John, location=Boston을 주면서 some.php에 요청을 보낸다. 요청이 성공적으로 수행되었으면, 그 응답이 alert()된다.
* 위 내용은 위키백과에 등록된 내용입니다.(http://ko.wikipedia.org/wiki/JQuery)
잠든거인의 jQuery ( 본좌 생각 )
jQuery가 무엇일까? 라는 고민을 가지고 jQuery를 처음 접하게 되었다.
jQuery를 알게 된 것은 아는 형이 회사에서 jQuery를 쓰고 있다는 애기를 듣고 난 후였다. 처음에는 Query라고 해서 SQL Query문을
만들어 주는 것이 아닌가?라느 생각을 가졌었다.(참 민망하다..) ㅡ.ㅡ;;
나중에야 검색을 하고 난후에야 웹 페이지에서 쓰이는 Javascript 프레임워크라는 걸 알게 된것이다.
프레임워크라고 하면 배우기만 하면 쓰기 편안한데, 막상 배우려면 시간이 꽤 많이 든다. 프로그래머라면 이 말에 공감이 갈 것이다.
어떤 프로그래머들은 프레임워크에 대해 안좋은 생각을 가지고 있는 분들고 있을 것이다. (뭐, 생각은 자유니깐..^^v)
본좌 또한 배우기에 귀찮다는 생각을 가지고 있었기에 열나게 DOMScript 만을 썼었다. 그러나 막상 개발에 들어가니 Javascript코드가
굉장히 길어지게 된것이다. 뭐 나만 보는 것이면 상관이 없었지만 다른 사람이 만약 내가 개발한 코드를 보고 분석할려면 시간이 좀
걸릴 것이다.
또한, 코드가 길다보니 마우스의 휠과 Ctrl + F 만을 열나게 사용해야만 했다. 본좌는 이게 가장 싫었다.
분할해서 Javascript 코드를 작성하면 되지 않냐! 라는 말 하시는 분들도 계시겠지만 본좌는 단순한 걸 좋아 한답니다. ^^v
그래서 코드를 경량화 시켜보고자 우선 Prototype을 배우고자 했지만, 갑자기 jQuery가 생각 났고, 누군가 Prototype보다 가볍다고
해서 jQuery를 쓰게 된 것이다.
우선 jQuery를 어떻게 사용하는 지를 알아 보자.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<script src="http://code.jquery.com/jquery-latest.js"></script>
<script>
$(document).ready(function(){
$("#my").css("border", "3px solid red")
});
</script>
</head>
<style>
div {
float: left;
width: 90px;
height: 90px;
padding: 5px;
margin: 5px;
background-color: #EEEEEE;
}
</style>
<body>
<div id='you'></div>
<div id='my'></div>
</body>
</html>
-------------- 실행 경과 -----------------

jQuery의 시작은
$(document).ready(function(){
// 여기에 코딩!!
});
이렇게 시작이 된다. 이제 가운데 부분에 코딩만 하면 되는 것이다.
$(document).ready(function(){..}) 이부분에 자세히 알아 보면
$(document).ready(function(){..}) == window.onload = function(){....} 이런 공식이 된다.
하지만 약간 다르다. 그 이유를 살펴보면
대부분 자바스크립트 프로그래머들은 브라우저의 document가 모두 로딩되고 난 후에 코딩을 하기 위해서 <body> 태그에
onload 이벤트를 사용하거나
window.onload = function(){....} 이와 같은 스크립트 코드를 넣는다.
그러나 이 경우에는 이미지까지 다운로드가 모두 완료 된 후 이벤트가 호출되기 때문에, 큰 이미지의 경우 실행속도가
늦은 것처럼 사용자에게 보일 수 있다. jQuery는 이러한 문제를 해결하기 위해 다음과 같은 이벤트를 제공한다.
$(document).ready(function(){
// 코딩........
})
이 이벤트는 브라우저의 document(DOM)객체가 준비가 되면 호출이 된다. 따라서 이미지 다운로드에 의한 지연이 없다.
위 코드를 생략하면
$(function(){
// 여기에다가 코딩을 하세요
});
이렇게 사용이 가능합니다.
이것으로 jQuery란 무엇인지 대한 강좌는 마치겠습니다.
[출처] JQuery란 과연 무엇인가?|작성자 잠든거인
SELECT ------------------ 5
FROM -------------------- 1
WHERE ------------------- 2
GROUP
HAVING ------------------- 4
ORDER BY ---------------- 6
http://www.soqool.com/
|
입력상자 한글/영문 설정하기 [style="ime-mode:active"]
|
style="ime-mode:auto"(자동변경)->한/영 전환가능
style="ime-mode:active"(한글모드) ->한/영전환가능
style="ime-mode:inactive"(영문모드)->오직영문
style="ime-mode:disabled"(영문모드)->한/영전환가능
style="ime-mode:deactivated"(한글모드)->한/영전환가능
//JAVA 입력받은 스트링이 숫자이면 true 문자이면 false를 리턴한다.
//JAVA To determine whether numeric or string value
//JAVA 数値か文字かどうかを判別
public static boolean isNumber(String str) {
boolean check = true;
for(int i = 0; i < str.length(); i++) {
if(!Character.isDigit(str.charAt(i)))
check = false;
break;
}// end if
} //end for
return check;
} //isNumber
<!DOCTYPE sqlMapConfig
PUBLIC "-//ibatis.apache.org//DTD SQL Map Config 2.0//EN"
"http://ibatis.apache.org/dtd/sql-map-config-2.dtd">
<sqlMapConfig>
<settings
cacheModelsEnabled="true"
enhancementEnabled="true"
lazyLoadingEnabled="true"
maxRequests="50"
maxSessions="25"
maxTransactions="10"
useStatementNamespaces="false"
/>
<!--Type aliases allow you to use a shorter name for long fully qualified class names. -->
<typeAlias alias="order" type="testdomain.Order"/>
<!-- Configure a built-in transaction manager. If you're using an
app server, you probably want to use its transaction manager
and a managed datasource -->
<transactionManager type="JDBC" commitRequired="false">
<dataSource type="JNDI">
<property name="DataSource" value="java:/comp/env/jdbc/DB"/>
</dataSource>
</transactionManager>
<!--sqlMap resource="C:\LuckyData\Project\Java1.5\data\ibatis\Member.xml"/-->
<sqlMap resource="board/board.xml"/>
<sqlMap resource="login/login.xml"/>
<sqlMap resource="db/dbChange.xml"/>
<sqlMap resource="statics/static.xml"/>
<!-- List more here...
<sqlMap resource="com/mydomain/data/Order.xml"/>
<sqlMap resource="com/mydomain/data/Documents.xml"/>
-->
</sqlMapConfig>
빨간색 부분처럼 바꿔준다. JNDI 물론 톰캣 SERVER.XML에 설정이 되있어야 겠다.
SERVER.XML
<Resource name="jdbc/IMARC" auth="Container" type="javax.sql.DataSource"
driverClassName="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@XXX.XXX.XXX.X:XXX:XXXX"
username="XXXX" password="XXXX maxActive="20" maxIdle="10" maxWait="10000" />
</Context>
각자설정에 알맞게 바꿔야겠죠?^^
출처 : http://matz.egloos.com/1442344
일반 문자열을 프로그래밍 언어용 문자열로 변환하기
원본 문자열
생성된 문자열
출처 : http://kr.geocities.com/kwon37xi/prog_string_generator.html
| 제목 : 서블렛 + JDBC 연동시 코딩 고려사항 -제2탄- 글쓴이: 이원영(javaservice) 2000/09/10 02:54:37 조회수:50292 줄수:1074 |
서블렛 + JDBC 연동시 코딩 고려사항 -제2탄- [JDBC Connection Pooling] 최근수정일자 : 2001.01.19 최근수정일자 : 2001.03.20(샘플예제추가) 최근수정일자 : 2001.10.22(디버깅을 위한 로직추가) 최근수정일자 : 2001.10.29(Oracle JDBC2.0 샘플추가) 최근수정일자 : 2001.11.08(윤한성님 도움 OracleConnectionCacheImpl 소스수정) 최근수정일자 : 2001.11.09(Trace/Debugging을 위한 장문의 사족을 담) 5. JDBC Connection Pooling 을 왜 사용해야 하는가 ? Pooling 이란 용어는 일반적인 용어입니다. Socket Connection Pooling, Thread Pooling, Resource Pooling 등 "어떤 자원을 미리 Pool 에 준비해두고 요청시 Pool에 있는 자원을 곧바로 꺼내어 제공하는 기능"인 거죠. JDBC Connection Pooling 은 JDBC를 이용하여 자바에서 DB연결을 할 때, 미리 Pool에 물리적인 DB 연결을 일정개수 유지하여 두었다가 어플리케이션에서 요구할 때 곧바로 제공해주는 기능을 일컫는 용어입니다. JDBC 연결시에, (DB 종류마다, 그리고 JDBC Driver의 타입에 따라 약간씩 다르긴 하지만 ) 대략 200-400 ms 가 소요 됩니다. 기껏 0.2 초 0.4 초 밖에 안되는 데 무슨 문제냐 라고 반문할수도 있습니다. 하지만, 위 시간은 하나의 연결을 시도할 때 그러하고, 100 - 200개를 동시에 연결을 시도하면 얘기가 완전히 달라집니다. 아래는 직접 JDBC 드라이버를 이용하여 연결할 때와 JDBC Connection Pooling 을 사용 할 때의 성능 비교 결과입니다. ------------------------------------------------------------------ 테스트 환경 LG-IBM 570E Notebook(CPU:???MHz , MEM:320MB) Windows NT 4.0 Service Pack 6 IBM WebSphere 3.0.2.1 + e-Fixes IBM HTTP Server 1.3.6.2 IBM UDB DB2 6.1 아래에 첨부한 파일는 자료를 만들때 사용한 JSP소스입니다. (첨부파일참조) [HttpConn.java] 간단한 Stress Test 프로그램 아래의 수치는 이 문서 이외에는 다른 용도로 사용하시면 안됩니다. 테스트를 저의 개인 노트북에서 측정한 것이고, 또한 테스트 프로그램 역시 직접 만들어한 것인 만큼, 공정성이나 수치에 대한 신뢰를 부여할 수는 없습니다. 그러나 JDBC Connection Pooling 적용 여부에 따른 상대적인 차이를 설명하기에는 충분할 것 같습니다. 테스트 결과 - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 매번 직접 JDBC Driver 연결하는 경우 java HttpConn http://localhost/db_jdbc.jsp -c <동시유저수> -n <호출횟수> -s 0 TOTAL( 1,10) iteration=10 , average=249.40 (ms), TPS=3.93 TOTAL(50,10) iteration=500 , average=9,149.84 (ms), TPS=4.83 TOTAL(100,10) iteration=1000 , average=17,550.76 (ms), TPS=5.27 TOTAL(200,10) iteration=2000 , average=38,479.03 (ms), TPS=4.89 TOTAL(300,10) iteration=3000 , average=56,601.89 (ms), TPS=5.01 - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - DB Connection Pooing 을 사용하는 경우 java HttpConn http://localhost/db_pool_cache.jsp -c <동시유저수> -n <호출횟수> -s 0 TOTAL(1,10) iteration=10 , average=39.00 (ms), TPS=23.26 TOTAL(1,10) iteration=10 , average=37.10 (ms), TPS=24.33 TOTAL(50,10) iteration=500 , average=767.36 (ms), TPS=45.27 TOTAL(50,10) iteration=500 , average=568.76 (ms), TPS=61.26 TOTAL(50,10) iteration=500 , average=586.51 (ms), TPS=59.79 TOTAL(50,10) iteration=500 , average=463.78 (ms), TPS=67.02 TOTAL(100,10) iteration=1000 , average=1,250.07 (ms), TPS=57.32 TOTAL(100,10) iteration=1000 , average=1,022.75 (ms), TPS=61.22 TOTAL(200,10) iteration=1462 , average=1,875.68 (ms), TPS=61.99 TOTAL(300,10) iteration=1824 , average=2,345.42 (ms), TPS=61.51 NOTE: average:평균수행시간, TPS:초당 처리건수 ------------------------------------------------------------------ 즉, JDBC Driver 를 이용하여 직접 DB연결을 하는 구조는 기껏 1초에 5개의 요청을 처리할 수 있는 능력이 있는 반면, DB Connection Pooling 을 사용할 경우는 초당 60여개의 요청을 처리할 수 있는 것으로 나타났습니다. 12배의 성능향상을 가져온거죠. (이 수치는 H/W기종과 측정방법, 그리고 어플리케이션에 따라 다르게 나오니 이 수치자체에 너무 큰 의미를 두진 마세요) 주의: 흔히 "성능(Performance)"을 나타낼 때, 응답시간을 가지고 얘기하는 경향이 있습니다. 그러나 응답시간이라는 것은 ActiveUser수가 증가하면 당연히 그에 따라 느려지게 됩니다. 반면 "단위시간당 처리건수"인 TPS(Transaction Per Second) 혹은 RPS(Request Per Second)는 ActiveUser를 지속적으로 끌어올려 임계점을 넘어서면, 특정수치 이상을 올라가지 않습니다. 따라서 성능을 얘기할 땐 평균응답시간이 아니라 "단위시간당 최대처리건수"를 이야기 하셔야 합니다. 성능(Performance)의 정의(Definition)은 "단위시간당 최대처리건수"임을 주지하세요. 성능에 관련한 이론은 아래의 문서를 통해, 함께 연구하시지요. [강좌]웹기반시스템하에서의 성능에 대한 이론적 고찰 http://www.javaservice.net/~java/bbs/read.cgi?m=resource&b=consult&c=r_p&n=1008701211 PS: IBM WebSphere V3 의 경우, Connection 을 가져올 때, JNDI를 사용하게 되는데 이때 사용되는 DataSource 객체를 매번 initialContext.lookup() 을 통해 가져오게 되면, 급격한 성능저하가 일어납니다.(NOTE: V4부터는 내부적으로 cache를 사용하여 성능이 보다 향상되었습니다) DataSource를 매 요청시마다 lookup 할 경우 다음과 같은 결과를 가져왔습니다. java HttpConn http://localhost/db_pool.jsp -c <동시유저수> -n <호출횟수> -s 0 TOTAL(1,10) iteration=10 , average=80.00 (ms), TPS=11.61 TOTAL(50,10) iteration=500 , average=2,468.30 (ms), TPS=16.98 TOTAL(50,10) iteration=500 , average=2,010.43 (ms), TPS=18.18 TOTAL(100,10) iteration=1000 , average=4,377.24 (ms), TPS=18.16 TOTAL(200,10) iteration=1937 , average=8,991.89 (ms), TPS=18.12 TPS 가 18 이니까 DataSource Cache 를 사용할 때 보다 1/3 성능밖에 나오지 않는 거죠. 6. JDBC Connection Pooling 을 사용하여 코딩할 때 고려사항 JDBC Connecting Pooling은 JDBC 1.0 스펙상에 언급되어 있지 않았습니다. 그러다보니 BEA WebLogic, IBM WebSphere, Oracle OAS, Inprise Server, Sun iPlanet 등 어플리케 이션 서버라고 불리는 제품들마다 그 구현방식이 달랐습니다. 인터넷에서 돌아다니는 Hans Bergsten 이 만든 DBConnectionManager.java 도 그렇고, JDF 에 포함되어 있는 패키지도 그렇고 각자 독특한 방식으로 개발이 되어 있습니다. JDBC를 이용하여 DB연결하는 대표적인 코딩 예를 들면 다음과 같습니다. ------------------------------------------------------------------ [BEA WebLogic Application Server] import java.sql.*; // Driver loading needed. static { try { Class.forName("weblogic.jdbc.pool.Driver").newInstance(); } catch (Exception e) { ... } } ...... Connection conn = null; Statement stmt = null; try { conn = DriverManager.getConnection("jdbc:weblogic:pool:<pool_name>", null); stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select ...."); while(rs.next()){ ..... } rs.close(); } catch(Exception e){ ..... } finally { if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( conn != null ) try{conn.close();}catch(Exception e){} } ------------------------------------------------------------------ IBM WebSphere Application Server 3.0.2.x / 3.5.x /* IBM WebSphere 3.0.2.x for JDK 1.1.8 */ //import java.sql.*; //import javax.naming.*; //import com.ibm.ejs.dbm.jdbcext.*; //import com.ibm.db2.jdbc.app.stdext.javax.sql.*; /* IBM WebSphere 3.5.x for JDK 1.2.2 */ import java.sql.*; import javax.sql.*; import javax.naming.*; // DataSource Cache 사용을 위한 ds 객체 static 초기화 private static DataSource ds = null; static { try { java.util.Hashtable props = new java.util.Hashtable(); props.put(Context.INITIAL_CONTEXT_FACTORY, "com.ibm.ejs.ns.jndi.CNInitialContextFactory"); Context ctx = null; try { ctx = new InitialContext(props); ds = (DataSource)ctx.lookup("jdbc/<data_source_name>"); } finally { if ( ctx != null ) ctx.close(); } } catch (Exception e) { .... } } ..... Connection conn = null; Statement stmt = null; try { conn = ds.getConnection("userid", "password"); stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select ...."); while(rs.next()){ ..... } rs.close(); } catch(Exception e){ ..... } finally { if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( conn != null ) try{conn.close();}catch(Exception e){} } ------------------------------------------------------------------ IBM WebSphere Application Server 2.0.x import java.sql.*; import com.ibm.servlet.connmgr.*; // ConnMgr Cache 사용을 위한 connMgr 객체 static 초기화 private static IBMConnMgr connMgr = null; private static IBMConnSpec spec = null; static { try { String poolName = "JdbcDb2"; // defined in WebSphere Admin Console spec = new IBMJdbcConnSpec(poolName, false, "com.ibm.db2.jdbc.app.DB2Driver", "jdbc:db2:<db_name>", // "jdbc:db2://ip_address:6789/<db_name>", "userid","password"); connMgr = IBMConnMgrUtil.getIBMConnMgr(); } catch(Exception e){ ..... } } ..... IBMJdbcConn cmConn = null; // "cm" maybe stands for Connection Manager. Statement stmt = null; try { cmConn = (IBMJdbcConn)connMgr.getIBMConnection(spec); Connection conn = jdbcConn.getJdbcConnection(); stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select ...."); while(rs.next()){ ..... } rs.close(); } catch(Exception e){ ..... } finally { if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( cmConn != null ) try{cmConn.releaseIBMConnection();}catch(Exception e){} } // NOTE: DO NOT "conn.close();" !! ------------------------------------------------------------------ Oracle OSDK(Oracle Servlet Development Kit) import java.sql.*; import oracle.ec.ctx.*; ..... oracle.ec.ctx.Trx trx = null; Connection conn = null; Statement stmt = null; try { oracle.ec.ctx.TrxCtx ctx = oracle.ec.ctx.TrxCtx.getTrxCtx(); trx = ctx.getTrx(); conn = trx.getConnection("<pool_name>"); stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select ...."); while(rs.next()){ ..... } rs.close(); } catch(Exception e){ ..... } finally { if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( conn != null ) try{ trx.close(conn,"<pool_name>");}catch(Exception e){} } // NOTE: DO NOT "conn.close();" !! ------------------------------------------------------------------ Hans Bergsten 의 DBConnectionManager.java import java.sql.*; ..... db.DBConnectionManager connMgr = null; Connection conn = null; Statement stmt = null; try { connMgr = db.DBConnectionManager.getInstance(); conn = connMgr.getConnection("<pool_name>"); stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select ...."); while(rs.next()){ ..... } rs.close(); } catch(Exception e){ ..... } finally { if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( conn != null ) connMgr.freeConnection("<pool_name>", conn); } // NOTE: DO NOT "conn.close();" !! ------------------------------------------------------------------ JDF 의 DB Connection Pool Framework import java.sql.*; import com.lgeds.jdf.*; import com.lgeds.jdf.db.*; import com.lgeds.jdf.db.pool.*; private static com.lgeds.jdf.db.pool.JdbcConnSpec spec = null; static { try { com.lgeds.jdf.Config conf = new com.lgeds.jdf.Configuration(); spec = new com.lgeds.jdf.db.pool.JdbcConnSpec( conf.get("gov.mpb.pbf.db.emp.driver"), conf.get("gov.mpb.pbf.db.emp.url"), conf.get("gov.mpb.pbf.db.emp.user"), conf.get("gov.mpb.pbf.db.emp.password") ); } catch(Exception e){ ..... } } ..... PoolConnection poolConn = null; Statement stmt = null; try { ConnMgr mgr = ConnMgrUtil.getConnMgr(); poolConn = mgr.getPoolConnection(spec); Connection conn = poolConnection.getConnection(); stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select ...."); while(rs.next()){ ..... } rs.close(); } catch(Exception e){ ..... } finally { if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( poolConn != null ) poolConn.release(); } // NOTE: DO NOT "conn.close();" !! ------------------------------------------------------------------ 여기서 하고픈 얘기는 DB Connection Pool 을 구현하는 방식에 따라서 개발자의 소스도 전부 제 각기 다른 API를 사용해야 한다는 것입니다. 프로젝트를 이곳 저곳 뛰어 본 분은 아시겠지만, 매 프로젝트마나 어플리케이션 서버가 다르고 지난 프로젝트에서 사용된 소스를 새 프로젝트에 그대로 적용하지 못하게 됩니다. JDBC 관련 API가 다르기 때문이죠. 같은 제품일지라도 버전업이 되면서 API가 변해버리는 경우도 있습니다. 예를 들면, IBM WebSphere 버전 2.0.x에서 버전 3.0.x로의 전환할 때, DB 연결을 위한 API가 변해버려 기존에 개발해둔 400 여개의 소스를 다 뜯어 고쳐야 하는 것과 같은 상황이 벌어질 수도 있습니다. 닷컴업체에서 특정 패키지 제품을 만들때도 마찬가지 입니다. 자사의 제품이 어떠한 어플리케이션 서버에서 동작하도록 해야 하느냐에 따라 코딩할 API가 달라지니 소스를 매번 변경해야만 하겠고, 특정 어플리케이션 서버에만 동작하게 하려니 마켓시장이 좁아지게 됩니다. IBM WebSphere, BEA WebLogic 뿐만 아니라 Apache JServ 나 JRun, 혹은 Tomcat 에서도 쉽게 포팅하길 원할 것입니다. 이것을 해결하는 방법은 우리들 "SE(System Engineer)"만의 고유한 "Connection Adapter 클래스"를 만들어서 사용하는 것입니다. 예를 들어 개발자의 소스는 이제 항상 다음과 같은 유형으로 코딩되면 어떻겠습니까 ? ----------------------------------------------------------- ..... ConnectionResource resource = null; Statement stmt = null; try { resource = new ConnectionResource(); Connection conn = resource.getConnection(); stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select ...."); while(rs.next()){ ..... } rs.close(); } catch(Exception e){ ..... } finally { if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( resource != null ) resource.release(); } // NOTE: DO NOT "conn.close();" !! ----------------------------------------------------------- 이 때 ConnectionResource 는 다음과 같은 형식으로 누군가 한분이 만들어 두면 되겠죠. ----------------------------------------------------------- import java.sql.*; public class ConnectionResource { private java.sql.Connection conn = null; public ConnectionResource() throws Exception { ...... conn = ..... GET Connection by Connection Pooling API } public Connection getConnection() throws Exception { return conn; } public void release(){ // release conn into "Connection Pool" ....... } } ----------------------------------------------------------- 예를 들어 IBM WebSphere Version 3.0.2.x 의 경우를 든다면 다음과 같이 될 겁니다. ----------------------------------------------------------- package org.jsn.connpool; /* * ConnectionResource V 1.0 * JDBC Connection Pool Adapter for IBM WebSphere V 3.0.x/3.5.x * Author: WonYoung Lee, javaservice@hanmail.net, 011-898-7904 * Last Modified : 2000.11.10 * NOTICS: You can re-distribute or copy this source code freely, * you can NOT remove the above subscriptions. */ /* IBM WebSphere 3.0.2.x for JDK 1.1.8 */ //import java.sql.*; //import javax.naming.*; //import com.ibm.ejs.dbm.jdbcext.*; //import com.ibm.db2.jdbc.app.stdext.javax.sql.*; /* IBM WebSphere 3.5.x for JDK 1.2.2 */ import java.sql.*; import javax.sql.*; import javax.naming.*; public class ConnectionResource { private static final String userid = "userid"; private static final String password = "password" private static final String datasource = "jdbc/<data_source_name>"; private static DataSource ds = null; private java.sql.Connection conn = null; public ConnectionResource() throws Exception { synchronized ( ConnectionResource.class ) { if ( ds == null ) { java.util.Hashtable props = new java.util.Hashtable(); props.put(Context.INITIAL_CONTEXT_FACTORY, "com.ibm.ejs.ns.jndi.CNInitialContextFactory"); Context ctx = null; try { ctx = new InitialContext(props); ds = (DataSource)ctx.lookup("jdbc/<data_source_name>"); } finally { if ( ctx != null ) ctx.close(); } } } conn = ds.getConnection( userid, password ); } public Connection getConnection() throws Exception { if ( conn == null ) throw new Exception("Connection is NOT avaiable !!"); return conn; } public void release(){ // release conn into "Connection Pool" if ( conn != null ) try { conn.close(); }catch(Excepton e){} conn = null; } } ----------------------------------------------------------- 만약 Hans Bersten 의 DBConnectionManager.java 를 이용한 Connection Pool 이라면 다음과 같이 만들어 주면 됩니다. ----------------------------------------------------------- package org.jsn.connpool; import java.sql.*; public class ConnectionResource { private String poolname = "<pool_name>"; private Connection conn = null; private db.DBConnectionManager connMgr = null; public ConnectionResource() throws Exception { connMgr = db.DBConnectionManager.getInstance(); conn = connMgr.getConnection(poolname); } public Connection getConnection() throws Exception { if ( conn == null ) throw new Exception("Connection is NOT avaiable !!"); return conn; } public void release(){ if ( conn != null ) { // Dirty Transaction을 rollback시키는 부분인데, 생략하셔도 됩니다. boolean autoCommit = true; try{ autoCommit = conn.getAutoCommit(); }catch(Exception e){} if ( autoCommit == false ) { try { conn.rollback(); }catch(Exception e){} try { conn.setAutoCommit(true); }catch(Exception e){} } connMgr.freeConnection(poolname, conn); conn = null; } } } ----------------------------------------------------------- 또, Resin 1.2.x 의 경우라면 다음과 같이 될 겁니다. ----------------------------------------------------------- package org.jsn.connpool; /* * ConnectionResource V 1.0 * JDBC Connection Pool Adapter for Resin 1.2.x * Author: WonYoung Lee, javaservice@hanmail.net, 011-898-7904 * Last Modified : 2000.10.18 * NOTICS: You can re-distribute or copy this source code freely, * you can NOT remove the above subscriptions. */ import java.sql.*; import javax.sql.*; import javax.naming.*; public class ConnectionResource { private static final String datasource = "jdbc/<data_source_name>"; private static final String userid = "userid"; private static final String password = "password" private static DataSource ds = null; private java.sql.Connection conn = null; public ConnectionResource() throws Exception { synchronized ( ConnectionResource.class ) { if ( ds == null ) { Context env = (Context) new InitialContext().lookup("java:comp/env"); ds = (DataSource) env.lookup(datasource); } } conn = ds.getConnection( userid, password ); } public Connection getConnection() throws Exception { if ( conn == null ) throw new Exception("Connection is NOT avaiable !!"); return conn; } public void release(){ // release conn into "Connection Pool" if ( conn != null ) try { conn.close(); }catch(Excepton e){} conn = null; } } ----------------------------------------------------------- Oracle 8i(8.1.6이상)에서 Oracle의 JDBC 2.0 Driver 자체가 제공하는 Connection Pool을 이용한다면 다음과 같이 될 겁니다. ----------------------------------------------------------- package org.jsn.connpool; /* * ConnectionResource V 1.0 * JDBC Connection Pool Adapter for Oracle JDBC 2.0 * Author: WonYoung Lee, javaservice@hanmail.net, 011-898-7904 * Last Modified : 2001.10.29 * NOTICS: You can re-distribute or copy this source code freely, * but you can NOT remove the above subscriptions. */ import java.sql.*; import javax.sql.*; import oracle.jdbc.driver.*; import oracle.jdbc.pool.*; public class ConnectionResource { private static final String dbUrl = "jdbc:oracle:thin@192.168.0.1:1521:ORCL"; private static final String userid = "userid"; private static final String password = "password" private static OracleConnectionCacheImpl oraclePool = null; private static boolean initialized = false; private java.sql.Connection conn = null; public ConnectionResource() throws Exception { synchronized ( ConnectionResource.class ) { if ( initialized == false ) { DriverManager.registerDriver (new oracle.jdbc.driver.OracleDriver()); oraclePool = new OracleConnectionCacheImpl(); oraclePool.setURL(dbUrl); oraclePool.setUser(userid); oraclePool.setPassword(password); oraclePool.setMinLimit(10); oraclePool.setMaxLimit(50); //oraclePool.setCacheScheme(OracleConnectionCacheImpl.FIXED_WAIT_SCHEME); // FIXED_WAIT_SCHEME(default), DYNAMIC_SCHEME, FIXED_RETURN_NULL_SCHEME //oraclePool.setStmtCacheSize(0); //default is 0 initialized = true; } } conn = oraclePool.getConnection(); } public Connection getConnection() throws Exception { if ( conn == null ) throw new Exception("Connection is NOT avaiable !!"); return conn; } public void release(){ // release conn into "Connection Pool" if ( conn != null ) try { conn.close(); }catch(Exception e){} conn = null; } } ----------------------------------------------------------- 또한 설령 Connection Pool 기능을 지금을 사용치 않더라도 향후에 적용할 계획이 있다면, 우선은 다음과 같은 Connection Adapter 클래스를 미리 만들어 두고 이를 사용하는 것이 효과적입니다. 향후에 이 클래스만 고쳐주면 되니까요. Oracle Thin Driver를 사용하는 경우입니다. ----------------------------------------------------------- import java.sql.*; public class ConnectionResource { private static final String userid = "userid"; private static final String password = "password" private static final String driver = "oracle.jdbc.driver.OracleDriver" private static final String url = "jdbc:oracle:thin@192.168.0.1:1521:ORCL"; private static boolean initialized = false; private java.sql.Connection conn = null; public ConnectionResource() throws Exception { synchronized ( ConnectionResource.class ) { if ( initialized == false ) { Class.forName(driver); initialized = true; } } conn = DriverManager.getConnection( url, userid, password ); } public Connection getConnection() throws Exception { if ( conn == null ) throw new Exception("Connection is NOT avaiable !!"); return conn; } public void release(){ if ( conn != null ) try { conn.close(); }catch(Excepton e){} conn = null; } } ----------------------------------------------------------- 프로그램의 유형이나, 클래스 이름이야 뭐든 상관없습니다. 위처럼 우리들만의 고유한 "Connection Adapter 클래스"를 만들어서 사용한다는 것이 중요하고, 만약 어플리케이션 서버가 변경된다거나, DB Connection Pooling 방식이 달라지면 해당 ConnectionResource 클래스 내용만 살짝 고쳐주면 개발자의 소스는 전혀 고치지 않아도 될 것입니다. NOTE: ConnectionResource 클래스를 만들때 주의할 것은 절대 Exception 을 클래스 내부에서 가로채어 무시하게 하지 말라는 것입니다. 그냥 그대로 throw 가 일어나게 구현하세요. 이렇게 하셔야만 개발자의 소스에서 "Exception 처리"를 할 수 있게 됩니다. NOTE2: ConnectionResource 클래스를 만들때 반드시 package 를 선언하도록 하세요. IBM WebSphere 3.0.x 의 경우 JSP에서 "서블렛클래스패스"에 걸려 있는 클래스를 참조할 때, 그 클래스가 default package 즉 package 가 없는 클래스일 경우 참조하지 못하는 버그가 있습니다. 통상 "Bean"이라 불리는 클래스 역시 조건에 따라 인식하지 않을 수도 있습니다. 클래스 다지인 및 설계 상으로 보더라도 package 를 선언하는 것이 바람직합니다. NOTE3: 위에서 "userid", "password" 등과 같이 명시적으로 프로그램에 박아 넣지 않고, 파일로 관리하기를 원한다면, 그렇게 하셔도 됩니다. JDF의 Configuration Framework 을 참조하세요. PS: 혹자는 왜 ConnectionResource 의 release() 메소드가 필요하냐고 반문할 수도 있습 니다. 예를 들어 개발자의 소스가 다음처럼 되도록 해도 되지 않느냐라는 거죠. ----------------------------------------------------------- ..... Connection conn = null; Statement stmt = null; try { conn = ConnectionResource.getConnection(); // <---- !!! stmt = conn.createStatement(); ..... } catch(Exception e){ ..... } finally { if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( conn != null ) try{conn.close();}catch(Exception e){} // <---- !!! } ----------------------------------------------------------- 이렇게 하셔도 큰 무리는 없습니다. 그러나, JDBC 2.0 을 지원하는 제품에서만 conn.close() 를 통해 해당 Connection 을 실제 close() 시키는 것이 아니라 DB Pool에 반환하게 됩니다. BEA WebLogic 이나 IBM WebSphere 3.0.2.x, 3.5.x 등이 그렇습니다. 그러나, 자체제작된 대부분의 DB Connection Pool 기능은 Connection 을 DB Pool에 반환하는 고유한 API를 가지고 있습니다. WebSphere Version 2.0.x 에서는 cmConn.releaseIBMConnection(), Oracle OSDK 에서는 trx.close(conn, "<pool_name">); Hans Bersten 의 DBConnectionManager 의 경우는 connMgr.freeConnection(poolname, conn); 등등 서로 다릅니다. 이러한 제품들까지 모두 지원하려면 "release()" 라는 우리들(!)만의 예약된 메소드가 꼭 필요하게 됩니다. 물론, java.sql.Connection Interface를 implements 한 별도의 MyConnection 을 만들어 두고, 실제 java.sql.Connection 을 얻은 후 MyConnection의 생성자에 그 reference를 넣어준 후, 이를 return 시에 넘기도록 하게 할 수 있습니다. 이때, MyConnection의 close() 함수를 약간 개조하여 DB Connection Pool로 돌아가게 할 수 있으니까요. PS: 하나 이상의 DB 를 필요로 한다면, 다음과 같은 생성자를 추가로 만들어서 구분케 할 수도 있습니다. ----------------------------------------------------------- .... private String poolname = "default_pool_name"; private String userid = "scott"; private String password = "tiger"; public ConnectionResource() throws Exception { initialize(); } public ConnectionResource(String poolname) throws Exception { this.poolname = poolname; initialize(); } public ConnectionResource(String poolname,String userid, String passwrod) throws Exception { this.poolname = poolname; this.userid = userid; this.password = password; initialize(); } private void initialize() throws Exception { .... } ... ----------------------------------------------------------- ------------------------------------------------------------------------------- 2001.03.20 추가 2001.10.22 수정 2001.11.09 수정(아래 설명을 추가함) 실 운영 사이트의 장애진단 및 튜닝을 다녀보면, 장애의 원인이 DataBase 연결개수가 지속적으로 증가하고, Connection Pool 에서 더이상 가용한 연결이 남아 있지 않아 발생하는 문제가 의외로 많습니다. 이 상황의 십중팔구는 개발자의 코드에서 Pool로 부터 가져온 DB연결을 사용하고 난 후, 이를 여하한의 Exception 상황에서도 다시 Pool로 돌려보내야 한다는 Rule 를 지키지 않아서 발생한 문제가 태반입니다. 이름만 말하면 누구나 알법한 큼직한 금융/뱅킹사이트의 프로그램소스에서도 마찬가지 입니다. 문제는 분명히 어떤 특정 응용프로그램에서 DB Connection 을 제대로 반환하지 않은 것은 분명한데, 그 "어떤 특정 응용프로그램"이 꼭집어 뭐냐 라는 것을 찾아내기란 정말 쉽지 않습니다. 정말 쉽지 않아요. 1초당 수십개씩의 Request 가 다양하게 들어 오는 상황에서, "netstat -n"으로 보이는 TCP/IP 레벨에서의 DB연결수는 분명히 증가 하고 있는데, 그 수십개 중 어떤 것이 문제를 야기하느냐를 도저히 못찾겠다는 것이지요. 사용자가 아무도 없는 새벽에 하나씩 컨텐츠를 꼭꼭 눌러 본들, 그 문제의 상황은 대부분 정상적인 로직 flow 에서는 나타나지 않고, 어떤 특별한 조건, 혹은 어떤 Exception 이 발생할 때만 나타날 수 있기 때문에, 이런 방법으로는 손발과 눈만 아프게 되곤 합니다. 따라서, 애초 부터, 이러한 상황을 고려하여, 만약, 개발자의 코드에서 실수로 DB연결을 제대로 Pool 에 반환하지 않았을 때, 그 개발자 프로그램 소스의 클래스 이름과 함께 Warnning 성 메세지를 남겨 놓으면, 되지 않겠느냐는 겁니다. Java 에서는 java.lang.Object 의 finalize() 라는 기막힌 메소드가 있습니다. 해당 Object instance의 reference 가 더이상 그 어떤 Thread 에도 남아 있지 않을 경우 JVM의 GC가 일어날 때 그 Object 의 finalize() 메소드를 꼭 한번 불러주니까요. 계속 반복되는 얘기인데, 아래 글에서 또한번 관련 의미를 찾을 수 있을 것입니다. Re: DB Connection Pool: Orphan and Idle Timeout http://www.javaservice.net/~java/bbs/read.cgi?m=devtip&b=servlet&c=r_p&n=1005294960 아래는 이것을 응용하여, Hans Bergsten 의 DBConnectionManager 를 사용하는 ConnectionAdapter 클래스를 만들어 본 샘플입니다. Trace/Debuging 을 위한 몇가지 기능이 첨가되어 있으며, 다른 ConnectionPool을 위한 Connection Adapter 를 만들때도 약간만 수정/응용하여 사용하실 수 있을 것입니다. /** * Author : Lee WonYoung, javaservice@hanmail.net * Date : 2001.03.20, 2001.10.22 */ import java.util.*; import java.sql.*; import java.io.*; import java.text.SimpleDateFormat; public class ConnectionResource { private boolean DEBUG_MODE = true; private String DEFAULT_DATASOURCE = "idb"; // default db name private long GET_CONNECTION_TIMEOUT = 2000; // wait only 2 seconds if no // avaiable connection in the pool private long WARNNING_MAX_ELAPSED_TIME = 3000; private SimpleDateFormat df = new SimpleDateFormat("yyyyMMdd/HHmmss"); private db.DBConnectionManager manager = null; private Connection conn = null; private String datasource = DEFAULT_DATASOURCE; private String caller = "unknown"; private long starttime = 0; private static int used_conn_count = 0; private static Object lock = new Object(); // detault constructor public ConnectionResource() { manager = db.DBConnectionManager.getInstance(); } // For debugging, get the caller object reference public ConnectionResource(Object caller_obj) { this(); if ( caller_obj != null ) caller = caller_obj.getClass().getName(); } public Connection getConnection() throws Exception { return getConnection(DEFAULT_DATASOURCE); } public Connection getConnection(String datasource) throws Exception { if ( conn != null ) throw new Exception ("You must release the connection first to get connection again !!"); this.datasource = datasource; // CONNECTION_TIMEOUT is very important factor for performance tuning conn = manager.getConnection(datasource, GET_CONNECTION_TIMEOUT); synchronized( lock ) { ++used_conn_count; } starttime = System.currentTimeMillis(); return conn; } // you don't have to get "connection reference" as parameter, // because we already have the referece as the privae member variable. public synchronized void release() throws Exception { if ( conn == null ) return; // The following is needed for some DB connection pool. boolean mode = true; try{ mode = conn.getAutoCommit(); }catch(Exception e){} if ( mode == false ) { try{conn.rollback();}catch(Exception e){} try{conn.setAutoCommit(true);}catch(Exception e){} } manager.freeConnection(datasource, conn); conn = null; int count = 0; synchronized( lock ) { count = --used_conn_count; } if ( DEBUG_MODE ) { long endtime = System.currentTimeMillis(); if ( (endtime-starttime) > WARNNING_MAX_ELAPSED_TIME ) { System.err.println(df.format(new java.util.Date()) + ":POOL:WARNNING:" + count + ":(" + (endtime-starttime) + "):" + "\t" + caller ); } } } // finalize() method will be called when JVM's GC time. public void finalize(){ // if "conn" is not null, this means developer did not release the "conn". if ( conn != null ) { System.err.println(df.format(new java.util.Date()) + ":POOL:ERROR connection was not released:" + used_conn_count + ":\t" + caller ); release(); } } } ------------------------------------------------------------------------------- 위의 Connection Adaptor 클래스를 Servlet 이나 JSP에서 사용할 때는 다음과 같이 사용할 수 있습니다. 사용법: DB Transaction 처리가 필요치 않을 때... ConnectionResource resource = null; Connection conn = null; Statement stmt = null; try{ // For debugging and tracing, I recommand to send caller's reference to // the adapter's constructor. resource = new ConnectionResource(this); // <--- !!! //resource = new ConnectionResource(); conn = resource.getConnection(); // or you can use another database name //conn = resource.getConnection("other_db"); stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select ..."); while(rs.next()){ ..... } rs.close(); } //catch(Exception e){ // // error handling if you want // .... //} finally{ if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( conn != null ) resource.release(); // <--- !!! } ------------------------------------------------------------------------------- 사용법: Transaction 처리가 필요할 때. ConnectionResource resource = null; Connection conn = null; Statement stmt = null; try{ // For debugging and tracing, I recommand to send caller's reference to // the adapter's constructor. resource = new ConnectionResource(this); //resource = new ConnectionResource(); conn = resource.getConnection(); // or you can use another database name //conn = resource.getConnection("other_db"); conn.setAutoCommit(false); // <--- !!! stmt = conn.createStatement(); stmt.executeUpdate("update ..."); stmt.executeUpdate("insert ..."); stmt.executeUpdate("update ..."); stmt.executeUpdate("insert ..."); stmt.executeUpdate("update ..."); int affected = stmt.executeUpdate("update...."); // depends on your business logic, if ( affected == 0 ) throw new Exception("NoAffectedException"); else if ( affected > 1 ) throw new Exception("TooManyAffectedException:" + affected); conn.commit(); //<<-- commit() must locate at the last position in the "try{}" } catch(Exception e){ // if error, you MUST rollback if ( conn != null ) try{conn.rollback();}catch(Exception e){} // another error handling if you want .... throw e; // <--- throw this exception if you want } finally{ if ( stmt != null ) try{stmt.close();}catch(Exception e){} if ( conn != null ) resource.release(); // <-- NOTE: autocommit mode will be // initialized } ----------------------------------------------------------------- PS: 더 깊이있는 내용을 원하시면 다음 문서들을 참조 하세요... JDF 제4탄 - DB Connection Pool http://www.javaservice.net/~java/bbs/read.cgi?m=jdf&b=framework&c=r_p&n=945156790 JDF 제5탄 - DB Connection Resource Framework http://www.javaservice.net/~java/bbs/read.cgi?m=jdf&b=framework&c=r_p&n=945335633 JDF 제6탄 - Transactional Connection Resource Framework http://www.javaservice.net/~java/bbs/read.cgi?m=jdf&b=framework&c=r_p&n=945490586 PS: IBM WebSphere의 JDBC Connection Pool 에 관심이 있다면 다음 문서도 꼭 참조 하세요... Websphere V3 Connection Pool 사용법 http://www.javaservice.net/~java/bbs/read.cgi?m=appserver&b=was&c=r_p&n=970209527 WebSphere V3 DB Connection Recovery 기능 고찰 http://www.javaservice.net/~java/bbs/read.cgi?m=appserver&b=was&c=r_p&n=967473008 ------------------------ NOTE: 2004.04.07 추가 그러나, 2004년 중반을 넘어서는 이 시점에서는, ConnectionResource와 같은 Wapper의 중요성이 별로 높이 평가되지 않는데, 그 이유는 Tomcat 5.0을 비롯한 대부분의 WAS(Web Application Server)가 자체의 Connection Poolinig기능을 제공하며, 그 사용법은 다음과 같이 JDBC 2.0에 준하여 모두 동일한 형태를 띠고 있기 때문입니다. InitialContext ctx = new InitialContext(); DataSource ds = (DataSoruce)ctx.lookup("java:comp/env/jdbc/ds"); Connection conn = ds.getConnection(); ... conn.close(); 결국 ConnectionResource의 release()류의 메소드는 Vendor별로, JDBC Connection Pool의 종류가 난무하던 3-4년 전에는 어플리케이션코드의 Vendor종속성을 탈피하기 위해 의미를 가졌으나, 지금은 굳이 필요가 없다고 보여 집니다. 단지, caller와 callee의 정보, 즉, 응답시간을 추적한다거나, close() 하지 않은 어플리케이션을 추적하는 의미에서의 가치만 남을 수 있습니다. (그러나, 이것도, IBM WebSphere v5의 경우, 개발자가 conn.close() 조차 하지 않을 지라도 자동을 해당 Thread의 request ending시점에 "자동반환"이 일어나게 됩니다.) --------------------- 2005.01.21 추가 JDBC Connection/Statement/ResultSet을 close하지 않은 소스의 위치를 잡아내는 것은 실제 시스템 운영 중에 찾기란 정말 모래사장에서 바늘찾기 같은 것이었습니다. 그러나, 제니퍼(Jennifer2.0)과 같은 APM을 제품을 적용하시면, 운영 중에, 어느 소스의 어느 위치에서 제대로 반환시키지 않았는지를 정확하게 찾아줍니다. 뿐만 아니라, 모든 SQL의 수행통계 및 현재 수행하고 있는 어플리케이션이 어떤 SQL을 수행중인지 실시간으로 확인되니, 성능저하를 보이는 SQL을 튜닝하는 것 등, 많은 부분들이 명확해져 가고 있습니다. 이젠 더이상 위 글과 같은 문서가 필요없는 세상을 기대해 봅니다. ------------------------------------------------------- 본 문서는 자유롭게 배포/복사 할 수 있으나 반드시 이 문서의 저자에 대한 언급을 삭제하시면 안됩니다 ================================================ 자바서비스넷 이원영 E-mail: javaservice@hanmail.net PCS:011-898-7904 ================================================ |
| 서블렛 + JDBC 연동시 코딩 고려사항 -제1탄- 글쓴이: 이원영(javaservice) 2000/09/06 05:19:47 조회수:92801 줄수:1544 |
최초작성일자: 2000/09/05 16:19:47
최근 수정일 : 2001.01.27
최근 수정일 : 2001.03.12(nested sql query issue)
최근 수정일 : 2001.03.13(transaction)
최근 수정일 : 2001.03.20(instance variables in JSP)
최근 수정일 : 2001.04.03(문맥수정)
최근 수정일 : 2002.02.06("close 할 땐 제대로..." 추가사항첨가)
최근 수정일 : 2002.02.25("transaction관련 추가")
최근 수정일 : 2002.06.11(PreparedStatement에 의한 ResultSet close 이슈)
최근 수정일 : 2002.06.18(PreparedStatement관련 추가)
최근 수정일 : 2002.12.30(Instance Variable 공유 1.2 추가)
다들 아실법한 단순한 얘깁니다만, 아직 많은 분들이 모르시는 것 같아 다시한번
정리합니다. 아래의 각각의 예제는 잘못 사용하고 계시는 전형적인 예들입니다.
1. 서블렛에서 instance variable 의 공유
1.1 서블렛에서 instance variable 의 공유 - PrintWriter -
다음과 같은 코드를 생각해 보겠습니다.
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class CountServlet extends HttpServlet {
private PrintWriter out = null; // <-------------- (1)
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException
{
res.setContentType("text/html");
out = res.getWriter();
for(int i=0;i<20;i++){
out.println("count= " + (i+1) + "<br>"); // <---- (2)
out.flush();
try{Thread.sleep(1000);}catch(Exception e){}
}
}
}
위의 CountServlet.java 를 컴파일하여 돌려 보면, 1초간격으로 일련의 숫자가 올라가는
것이 보일 겁니다.(서블렛엔진의 구현방식에 따라 Buffering 이 되어 20초가 모두 지난
후에서 퍽 나올 수도 있습니다.)
혼자서 단일 Request 를 날려 보면, 아무런 문제가 없겠지만, 이제 브라우져 창을 두개 이상
띄우시고 10초의 시간 차를 두시면서 동시에 호출해 보세요... 이상한 증상이 나타날
겁니다. 먼저 호출한 창에는 10 까지 정도만 나타나고, 10초 뒤에 호출한 창에서는 먼저
호출한 창에서 나타나야할 내용들까지 덤으로 나타나는 것을 목격할 수 있을 겁니다.
이는 서블렛의 각 호출은 Thread 로 동작하여, 따라서, 각 호출은 위의 (1) 에서 선언한
instance variable 들을 공유하기 때문에 나타나는 문제입니다.
위 부분은 다음과 같이 고쳐져야 합니다.
public class CountServlet extends HttpServlet {
//private PrintWriter out = null;
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException
{
PrintWriter out = null; // <--- 이 쪽으로 와야죠 !!!
res.setContentType("text/html");
out = res.getWriter();
for(int i=0;i<20;i++){
out.println("count= " + (i+1) + "<br>"); // <---- (2)
out.flush();
try{Thread.sleep(1000);}catch(Exception e){}
}
}
}
국내 몇몇 Servlet 관련 서적의 일부 예제들이 위와 같은 잘못된 형태로 설명한
소스코드들이 눈에 띕니다. 빠른 시일에 바로 잡아야 할 것입니다.
실제 프로젝트 환경에서 개발된 실무시스템에서도, 그러한 책을 통해 공부하신듯, 동일한
잘못된 코딩을 하고 있는 개발자들이 있습니다. 결과적으로 테스트 환경에서는 나타나지
않더니만, 막상 시스템을 오픈하고나니 고객으로 부터 다음과 같은 소리를 듣습니다.
"내 데이타가 아닌데 남의 데이타가 내 화면에 간혹 나타나요. refresh 를 누르면 또,
제대로 되구요" .....
1.2 서블렛에서 instance variable 의 공유
앞서의 경우와 의미를 같이하는데, 다음과 같이 하면 안된다는 얘기지요.
public class BadServlet extends HttpServlet {
private String userid = null;
private String username = null;
private int hitcount = 0;
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException
{
res.setContentType("text/html");
PrintWriter out = res.getWriter();
userid = request.getParameter("userid");
username = request.getParameter("username");
hitcount = hitcount + 1;
....
}
}
새로운 매 HTTP 요청마다 userid/username변수는 새롭게 할당됩니다. 문제는 그것이 특정
사용자에 한하여 그러한 것이 아니라, BadServlet의 인스턴스(instance)는 해당
웹컨테이너(Web Container)에 상에서 (예외경우가 있지만) 단 하나만 존재하고, 서로 다른
모든 사용자들의 서로 다른 모든 요청들에 대해서 동일한 userid/username 및 count 변수를
접근하게 됩니다. 따라서, 다음과 같이 메소드 안으로 끌어들여 사용하여야 함을 강조합니다.
public class BadServlet extends HttpServlet {
//private String userid = null; // <---- !!
//private String username = null; // <---- !!
private int hitcount = 0;
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException
{
res.setContentType("text/html");
PrintWriter out = res.getWriter();
String userid = request.getParameter("userid"); // <---- !!
String username = request.getParameter("username"); // <---- !!
//또한, instance 변수에 대한 접근은 적어도 아래처럼 동기화를 고려해야...
synchronized(this){ hitcount = hitcount + 1; }
....
}
}
1.3 서블렛에서 instance variable 의 공유 - DataBase Connection -
public class TestServlet extends HttpServlet {
private final static String drv = "oracle.jdbc.driver.OracleDriver";
private final static String url = "jdbc:orache:thin@210.220.251.96:1521:ORA8i";
private final static String user = "scott";
private final static String password = "tiger";
private ServletContext context;
private Connection conn = null; <--- !!!
private Statement stmt = null; <------ !!!
private ResultSet rs = null; <------ !!!
public void init(ServletConfig config) throws ServletException {
super.init(config);
context = config.getServletContext();
try {
Class.forName(drv);
}
catch (ClassNotFoundException e) {
throw new ServletException("Unable to load JDBC driver:"+ e.toString());
}
}
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException, SQLException
{
String id = req.getParameter("id");
conn = DriverManager.getConnection(url,user,password); ---- (1)
stmt = conn.createStatement(); ---------- (2)
rs = stmt.executeQuery("select .... where id = '" + id + "'"); ----- (3)
while(rs.next()) { ----------- (4)
...... --------- (5)
}
rs.close(); -------- (6)
stmt.close(); ---- (7)
conn.close(); --- (8)
.....
}
}
위에서 뭐가 잘못되었죠? 여러가지가 있겠지만, 그 중에 하나가 java.sql.Connection과
java.sql.Statment, java.sql.ResultSet을 instance variable 로 사용하고 있다는 것입니다.
이 서블렛은 사용자가 혼자일 경우는 아무런 문제를 야기하지 않습니다. 그러나 여러사람이
동시에 이 서블렛을 같이 호출해 보면, 이상한 증상이 나타날 것입니다.
그 이유는 conn, stmt, rs 등과 같은 reference 들을 instance 변수로 선언하여 두었기
때문에 발생합니다. 서블렛은 Thread로 동작하며 위처럼 instance 변수 영역에 선언해 둔
reference 들은 doGet(), doPost() 를 수행하면서 각각의 요청들이 동시에 공유하게 됩니다.
예를 들어, 두개의 요청이 약간의 시간차를 두고 비슷한 순간에 doGet() 안으로 들어왔다고
가정해 보겠습니다.
A 라는 요청이 순차적으로 (1), (2), (3) 까지 수행했을 때, B 라는 요청이 곧바로 doGet()
안으로 들어올 수 있습니다. B 역시 (1), (2), (3) 을 수행하겠죠...
이제 요청 A 는 (4) 번과 (5) 번을 수행하려 하는데, 가만히 생각해 보면, 요청B 로 인해
요청A에 의해 할당되었던 conn, stmt, rs 의 reference 들은 바뀌어 버렸습니다.
결국, 요청 A 는 요청 B 의 결과를 가지고 작업을 하게 됩니다. 반면, 요청 B 는
요청 A 의 의해 rs.next() 를 이미 수행 해 버렸으므로, rs.next() 의 결과가 이미 close
되었다는 엉뚱한 결과를 낳고 마는 거죠...
다른 쉬운 얘기로 설명해 보면, A, B 두사람이 식탁에 앉아서 각자 자신이 준비해 온 사과를
하나씩 깎아서 식탁 위의 접시에 올려 놓고 나중에 먹어려 하는 것과 동일합니다. A 라는
사람이 열심히 사과를 깎아 접시에 담아둘 때, B 라는 사람이 들어와서 A가 깎아둔 사과를
버리고 자신이 깎은 사과를 대신 접시에 담아 둡니다. 이제 A라는 사람은 자신이 깎아서
담아 두었다고 생각하는 그 사과를 접시에서 먹어버립니다. 곧이어 B라는 사람이 자신의
사과를 접시에서 먹어려 하니 이미 A 가 먹고 난 후 였습니다. 이는 접시를 두 사람이
공유하기 때문에 발생하는 문제잖습니까.
마찬가지로 서블렛의 각 Thread는 instance variable 를 공유하기 때문에 동일한 문제들을
발생하게 됩니다.
따라서 최소한 다음처럼 고쳐져야 합니다.
public class TestServlet extends HttpServlet {
private final static String drv = "...";
private final static String url = "....";
private final static String user = "...";
private final static String password = "...";
private ServletContext context;
public void init(ServletConfig config) throws ServletException {
super.init(config);
context = config.getServletContext();
try {
Class.forName(drv);
}
catch (ClassNotFoundException e) {
throw new ServletException("Unable to load JDBC driver:"+ e.toString());
}
}
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException, SQLException
{
Connection conn = null; <----- 이곳으로 와야죠..
Statement stmt = null; <-------
ResultSet rs = null; <---------
String id = req.getParameter("id");
conn = DriverManager.getConnection(url,user,password);
stmt = conn.createStatement();
rs = stmt.executeQuery("select ..... where id = '" + id + "'");
while(rs.next()) {
......
}
rs.close();
stmt.close();
conn.close();
.....
}
}
1.4 JSP에서 Instance Variable 공유
JSP에서 아래처럼 사용하는 경우가 위의 경우와 동일한 instance 변수를 공유하는 경우가
됩니다.
---------------------------------------------------------
<%@ page session=.... import=.... contentType=........ %>
<%!
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
String userid = null;
%>
<html><head></head><body>
<%
........
conn = ...
stmt = .....
uesrid = ......
%>
</body></html>
---------------------------------------------------------
마찬가지로 위험천만한 일이며, 여러 Thread 에 의해 그 값이 변할 수 있는 변수들은
<%! ... %> 를 이용하여 선언하시면 안됩니다. 이처럼 instance 변수로 사용할 것은
다음 처럼, 그 값이 변하지 않는 값이거나, 혹은 공유변수에 대한 특별한 관리를
하신 상태에서 하셔야 합니다.
<%! private static final String USERID = "scott";
private static final String PASSWORD = "tiger";
%>
JSP에서의 이와 같은 잘못된 유형도, 앞선 서블렛의 경우처럼 일부 국내 JSP관련
서적에서 발견됩니다. 해당 서적의 저자는 가능한 빨리 개정판을 내셔서 시정하셔야
할 것입니다. 해당 책은 출판사나 책의 유형, 그리고 글자체로 추정건데, 초보자가
쉽게 선택할 법한 책인 만큼 그 파급력과 영향력이 너무 큰 듯 합니다.
이와 같은 부분이 실 프로젝트에서 존재할 경우, 대부분 시스템 오픈 첫날 쯤에
문제를 인식하게 됩니다. Connection reference 가 엎어쳐지므로 Pool 에 반환이
일어나지 않게 되고, 이는 "connection pool"의 가용한 자원이 부하가 얼마 없음에도
불구하고 모자라는 현상으로 나타나며, 때론 사용자의 화면에서는 엉뚱한 다른
사람의 데이타가 나타나거나, SQLException 이 나타납니다.
NOTE: 어떻게하란 말입니까? 각 호출간에 공유되어서는 안될 변수들은 <%! ...%> 가
아니라, <% ... %> 내에서 선언하여 사용하란 얘깁니다. JSP가 Pre-compile되어
Servlet형태로 변환될 때, <%! ... %>는 서블렛의 instance variable로 구성되는 반면,
<% ... %>는 _jspService() 메소드 내의 method variable로 구성됩니다.
2. 하나의 Connection을 init()에서 미리 연결해 두고 사용하는 경우.
public class TestServlet extends HttpServlet {
private final static String drv = "oracle.jdbc.driver.OracleDriver";
private final static String url = "jdbc:orache:thin@210.220.251.96:1521:ORA8i";
private final static String user = "scott";
private final static String password = "tiger";
private ServletContext context;
private Connection conn = null; <--- !!!
public void init(ServletConfig config) throws ServletException {
super.init(config);
context = config.getServletContext();
try {
Class.forName(drv);
conn = DriverManager.getConnection(url,user,password);
}
catch (ClassNotFoundException e) {
throw new ServletException("Unable to load JDBC driver:"+ e.toString());
}
catch (SQLException e) {
throw new ServletException("Unable to connect to database:"+ e.toString());
}
}
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException, SQLException
{
Statement stmt = null;
ResultSet rs = null;
String id = req.getParameter("id");
stmt = conn.createStatement();
rs = stmt.executeQuery("select ..... where id = '" + id + "'");
while(rs.next()) {
......
}
rs.close();
stmt.close();
.....
}
public void destroy() {
if ( conn != null ) try {conn.close();}catch(Exception e){}
}
}
위는 뭐가 잘못되었을 까요? 서블렛당 하나씩 java.sql.Connection 을 init()에서 미리
맺어 두고 사용하는 구조 입니다.
얼핏 생각하면 아무런 문제가 없을 듯도 합니다. doGet() 내에서 별도의 Statement와
ResultSet 을 사용하고 있으니, 각 Thread는 자신만의 Reference를 갖고 사용하게 되니까요.
이 구조는 크게 세가지의 문제를 안고 있습니다. 하나는 DB 연결자원의 낭비를 가져오며,
두번째로 수많은 동시사용자에 대한 처리한계를 가져오고, 또 마지막으로 insert, update,
delete 와 같이 하나 이상의 SQL문장을 수행하면서 단일의 Transaction 처리를 보장받을
수 없다는 것입니다.
1) DB 자원의 낭비
위의 구조는 서블렛당 하나씩 java.sql.Connection 을 점유하고 있습니다. 실 프로젝트에서
보통 서블렛이 몇개나 될까요? 최소한 100 개에서 400개가 넘어 갈 때도 있겠죠?
그럼 java.sql.Connection에 할당 되어야 할 "DB연결갯수"도 서블렛 갯수 많큼 필요하게
됩니다. DB 연결 자원은 DB 에서 설정하기 나름이지만, 통상 maximum 을 셋팅하기
마련입니다. 그러나 아무런 요청이 없을 때도 400 여개의 DB연결이 연결되어 있어야 한다는
것은 자원의 낭비입니다.
2) 대량의 동시 사용자 처리 불가.
또한, 같은 서블렛에 대해 동시에 100 혹은 그 이상의 요청이 들어온다고 가정해 보겠습
니다. 그럼 같은 java.sql.Connection 에 대해서 각각의 요청이 conn.createStatement() 를
호출하게 됩니다.
문제는 하나의 Connection 에 대해 동시에 Open 할 수 있는 Statement 갯수는 ( 이 역시
DB 에서 셋팅하기 나름이지만 ) maximum 제한이 있습니다. Oracle 의 경우 Default는 50
입니다. 만약 이 수치 이상을 동시에 Open 하려고 하면 "maximum open cursor exceed !"
혹은 "Limit on number of statements exceeded"라는 SQLExceptoin 을 발생하게 됩니다.
예를 들어 다음과 같은 프로그램을 실행시켜 보세요.
public class DbTest {
public static void main(String[] args) throws Exception {
Class.forName("jdbc driver...");
Connection conn = DriverManager.getConnection("url...","id","password");
int i=0;
while(true) {
Statement stmt = conn.createStatement();
System.out.println( (++i) + "- stmt created");
}
}
}
과연 몇개 까지 conn.createStement() 가 수행될 수 있을까요? 이는 DB에서 설정하기 나름
입니다. 중요한 것은 그 한계가 있다는 것입니다.
또한 conn.createStatement() 통해 만들어진 stmt 는 java.sql.Connection 의 자원이기
때문에 위처럼 stmt 의 reference 가 없어졌다고 해도 GC(Garbage Collection)이 되지
않습니다.
3) Transaction 중복현상 발생
예를 들어 다음과 같은 서비스가 있다고 가정해 보겠습니다.
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException, SQLException
{
Statement stmt = null;
String id = req.getParameter("id");
try {
conn.setAutoCommit(false);
stmt = conn.createStatement();
stmt.executeUpdate("update into XXXX..... where id = " + id + "'");
stmt.executeUpdate("delete from XXXX..... where id = " + id + "'");
stmt.executeUpdate(".... where id = " + id + "'");
stmt.executeUpdate(".... where id = " + id + "'");
conn.commit();
}
catch(Exception e){
try{conn.rollback();}catch(Exception e){}
}
finally {
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
conn.setAutoCommit(true);
}
.....
}
아무런 문제가 없을 듯도 합니다. 그러나 위의 서비스를 동시에 요청하게 되면, 같은
java.sql.Connection 을 갖고 작업을 하고 있으니 Transaction 이 중첩되게 됩니다.
왜냐면, conn.commit(), conn.rollback() 과 같이 conn 이라는 Connection 에 대해서
Transaction 이 관리되기 때문입니다. 요청 A 가 총 4개의 SQL문장 중 3개를 정상적으로
수행하고 마지막 4번째의 SQL문장을 수행하려 합니다. 이 때 요청 B가 뒤따라 들어와서
2개의 SQL 문장들을 열심히 수행했습니다. 근데, 요청 A에 의한 마지막 SQL 문장
수행중에 SQLException 이 발생했습니다. 그렇담 요청 A 는 catch(Exception e) 절로
분기가 일어나고 conn.rollback() 을 수행하여 이미 수행한 3개의 SQL 수행들을 모두
rollback 시킵니다. 근데,,, 문제는 요청 B 에 의해 수행된 2개의 SQL문장들도 같이
싸잡아서 rollback() 되어 버립니다. 왜냐면 같은 conn 객체니까요. 결국, 요청B 는
영문도 모르고 마지막 2개의 SQL문장만 수행한 결과를 낳고 맙니다.
따라서 정리하면, Connection, Statement, ResultSet 는 doGet() , doPost() 내에서
선언되고 사용되어져야 합니다.
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException, SQLException
{
Connection conn = null; <----- 이곳으로 와야죠..
Statement stmt = null; <-------
ResultSet rs = null; <---------
.....
}
3. Exception 이 발생했을 때도 Connection 은 닫혀야 한다 !!
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException, SQLException
{
String id = req.getParameter("id");
Connection conn = DriverManager.getConnection("url...","id","password");
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("ssselect * from XXX where id = '" + id + "'");
while(rs.next()) {
......
}
rs.close();
stmt.close();
conn.close();
.....
}
위에선 뭐가 잘못되었을까요? 네, 사실 특별히 잘못된 것 없습니다. 단지 SQL문장에 오타가
있다는 것을 제외하곤.... 근데, 과연 그럴까요?
SQLException 이라는 것은 Runtime 시에 발생합니다. DB 의 조건이 맞지 않는다거나
개발기간 중에 개발자의 실수로 SQL문장에 위처럼 오타를 적을 수도 있죠.
문제는 Exception 이 발생하면 마지막 라인들 즉, rs.close(), stmt.close(), conn.close()
가 수행되지 않는다는 것입니다.
java.sql.Connection 은 reference 를 잃더라도 JVM(Java Virtual Machine)의 GC(Garbage
Collection) 대상이 아닙니다. 가뜩이나 모자라는 "DB연결자원"을 특정한 어플리케이션이
점유하고 놓아 주지 않기 때문에 얼마안가 DB Connection 을 더이상 연결하지 못하는
사태가 발생합니다.
따라서 다음처럼 Exception 이 발생하든 발생하지 않든 반드시 java.sql.Connection 을
close() 하는 로직이 꼭(!) 들어가야 합니다.
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException, SQLException
{
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
String id = req.getParameter("id");
try {
conn = DriverManager.getConnection("url...","id","password");
stmt = conn.createStatement();
rs = stmt.executeQuery("sselect * from XXX where id = '" + id + "'");
while(rs.next()) {
......
}
rs.close();
stmt.close();
}
finally {
if ( conn != null ) try {conn.close();}catch(Exception e){}
}
.....
}
참고로, 실프로젝트의 진단 및 튜닝을 나가보면 처음에는 적절한 응답속도가 나오다가
일정한 횟수 이상을 호출하고 난 뒤부터 엄청 응답시간이 느려진다면, 십중팔구는 위처럼
java.sql.Connection 을 닫지 않아서 생기는 문제입니다.
가용한 모든 Connection 을 연결하여 더이상 연결시킬 Connection 자원을 할당할 수 없을
때, 대부분 timewait 이 걸리기 때문입니다. 일단 DB관련한 작업이 들어오는 족족
timewait에 빠질 경우, "어플리케이션서버"에서 동시에 처리할 수 있는 최대 갯수만큼
호출이 차곡차곡 쌓이는 건 불과 몇분 걸리지 않습니다. 그 뒤부터는 애궂은 dummy.jsp
조차 호출이 되지 않게 되고, 누군가는 "시스템 또 죽었네요"라며 묘한 웃음을 짓곤
하겠죠....
4. Connection 뿐만 아니라 Statement, ResultSet 도 반드시 닫혀야 한다 !!
4.1 3번의 예제에서 Connection 의 close() 만 고려하였지 Statement 나 ResultSet 에 대한
close는 전혀 고려 하지 않고 있습니다. 무슨 문제가 있을까요? Statement 를 닫지 않아도
Connection 을 닫았으니 Statement 나 ResultSet 은 자동으로 따라서 닫히는 것 아니냐구요?
천만의 말씀, 만만의 콩깎지입니다.
만약, DB Connection Pooling 을 사용하지 않고 직접 JDBC Driver 를 이용하여 매번 DB
연결을 하였다가 끊는 구조라면 문제가 없습니다.
그러나 DB Connection Pooling 은 이젠 보편화되어 누구나 DB Connection Pooling 을 사용
해야한다는 것을 알고 있습니다. 그것이 어플리케이션 서버가 제공해 주든, 혹은 작은
서블렛엔진에서 운영하고 있다면 직접 만들거나, 인터넷으로 돌아다니는 남의 소스를 가져다
사용하고 있을 겁니다.
이처럼 DB Connection Pooling 을 사용하고 있을 경우는 Conneciton 이 실제 close()되는
것이 아니라 Pool에 반환되어 지게 되는데, 결국 reference가 사리지지 않기 때문에 GC시점에
자동 close되지 않게 됩니다.
특정 Connection 에서 열어둔 Statement 를 close() 하지 않은채 그냥 반환시켜 놓게 되면,
언젠가는 그 Connection 은 다음과 같은 SQLException 을 야기할 가능성을 내포하게 됩니다.
Oracle :
java.sql.SQLException : ORA-01000: maximum open cursor exceeded !!
(최대열기 커서수를 초과했습니다)
UDB DB2 :
COM.ibm.db2.jdbc.DB2Exception: [IBM][JDBC 드라이버] CLI0601E 유효하지 않은
명령문 핸들 또는 명령문이 닫혔습니다. SQLSTATE=S1000
COM.ibm.db2.jdbc.DB2Exception: [IBM][CLI Driver] CLI0129E 핸들(handle)이
더이상 없습니다. SQLSTATE=HY014
COM.ibm.db2.jdbc.DB2Exception: [IBM][CLI Driver][DB2/NT] SQL0954C 응용프로그램
힙(heap)에 명령문을 처리하기 위해 사용 가능한 저장영역이 충분하지 않습니다.
SQLSTATE=57011
이유는 앞 2)번글에서 이미 언급드렸습니다. 보다 자세한 기술적 내용은 아래의 글을
참고하세요.
Connection/Statement 최대 동시 Open 수
http://www.javaservice.net/~java/bbs/read.cgi?m=devtip&b=jdbc&c=r_p&n=972287002
따라서 또다시 3번의 소스는 다음과 같은 유형으로 고쳐져야 합니다.
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException, SQLException
{
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
String id = req.getParameter("id");
try {
conn = ...<getConnection()>...; // (편의상 생략합니다.)
stmt = conn.createStatement();
rs = stmt.executeQuery("sselect * from XXX where id = '" + id + "'");
while(rs.next()) {
......
}
// rs.close();
// stmt.close();
}
finally {
if ( rs != null ) try {rs.close();}catch(Exception e){}
if ( stmt != null ) try {stmt.close();}catch(Exception e){} // <-- !!!!
if ( conn != null ) ...<releaseConnection()>...; // (편의상 생략)
}
.....
}
4.2 사실 위와 같은 구조에서, java.sql.Statement의 쿼리에 의한 ResultSet의 close()에
대한 것은 그리 중요한 것은 아닙니다. ResultSet은 Statement 가 close() 될 때 함께
자원이 해제됩니다. 따라서 다음과 같이 하셔도 됩니다.
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException, SQLException
{
Connection conn = null;
Statement stmt = null;
String id = req.getParameter("id");
try {
conn = ...<getConnection()>...;
stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("sselect * from XXX where id = '" + id + "'");
while(rs.next()) {
......
}
rs.close(); //<--- !!!
}
finally {
// if ( rs != null ) try {rs.close();}catch(Exception e){}
if ( stmt != null ) try {stmt.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
.....
}
4.3 가장 대표적으로 잘못 프로그래밍하고 있는 예를 들라면 다음과 같은 유형입니다.
Connection conn = null;
try {
conn = ...<getConnection()>....;
Statement stmt = conn.createStatement();
stmt.executeUpdate("...."); <--- 여기서 SQLException 이 일어나면...
.....
.....
..... <-- 만약,이쯤에서 NullPointerException 이 일어나면 ?
.....
stmt.close(); <-- 이것을 타지 않음 !!!
}
finally{
if ( conn != null ) ...<releaseConnection()>...;
}
4.4 Statement 가 close() 되지 않는 또 하나의 경우가 다음과 같은 경우입니다.
Connection conn = null;
Statement stmt = null;
try {
conn = .....
stmt = conn.createStatement(); // ....(1)
rs = stmt.executeQuery("select a from ...");
.....
rs.close();
stmt = conn.createStatement(); // ....(2)
rs = stmt.executeQuery("select b from ...");
....
}
finally{
if ( rs != null ) try {rs.close();}catch(Exception e){}
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
if ( conn != null ) ....
}
즉, 두번 stmt = conn.createStatement() 를 수행함으로써, 먼저 생성된 stmt 는
(2)번에 의해 그 reference 가 엎어쳐버리게 되어 영원히 close() 되지 않은채
남아 있게 됩니다.
이 경우, (2)번 문장을 주석처리하여야 겠지요. 한번 생성된 Statement 로 여러번
Query 를 수행하면 됩니다.
Connection conn = null;
Statement stmt = null;
try {
conn = .....
stmt = conn.createStatement(); // ....(1)
rs = stmt.executeQuery("select a from ...");
.....
rs.close();
// stmt = conn.createStatement(); // <--- (2) !!!
rs = stmt.executeQuery("select b from ...");
....
}
finally{
if ( rs != null ) try {rs.close();}catch(Exception e){}
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
if ( conn != null ) ....
}
4.5 Statement 뿐만 아니라 PreparedStatement 를 사용할 때로 마찬가지 입니다.
....
PreparedStatement pstmt = conn.prepareStatement("select ....");
....
이렇게 만들어진 pstmt 도 반드시 pstmt.close() 되어야 합니다.
예를 들면, 다음과 같은 코드를 생각할 수 있습니다.
Connection conn = null;
try {
conn = ...<getConnection()>...;
PreparedStatement pstmt = conn.prepareStatement("select .... ?...?");
pstmt.setString(1,"xxxx");
pstmt.setString(2,"yyyy");
ResultSet rs = pstmt.executeQuery(); <--- 여기서 SQLException 이 일어나면
while(rs.next()){
....
}
rs.close();
pstmt.close(); <-- 이것을 타지 않음 !!!
}
finally{
if ( conn != null ) ...<releaseConnection()>...;
}
따라서 같은 맥락으로 다음과 같이 고쳐져야 합니다.
Connection conn = null;
PreparedStatement pstmt = null; // <-------- !!
ResultSet rs = null;
try {
conn = ...<getConnection()>...;
pstmt = conn.prepareStatement("select .... ?...?");
pstmt.setString(1,"xxxx");
pstmt.setString(2,"yyyy");
rs = pstmt.executeQuery(); <--- 여기서 SQLException 이 일어나더라도...
while(rs.next()){
....
}
//rs.close();
//pstmt.close();
}
finally{
if ( rs != null ) try {rs.close();}catch(Exception e){}
if ( pstmt != null ) try {pstmt.close();}catch(Exception e){} // <-- !!!!
if ( conn != null ) ...<releaseConnection()>...;
}
4.6 PreparedStatement 에 관련해서 다음과 같은 경우도 생각할 수 있습니다.
4.6.1 앞서의 4.4에서 Statement를 createStatement() 연거푸 두번 생성하는 것과
동일하게 PreparedStatement에서도 주의하셔야 합니다. 예를 들면 다음과 같습니다.
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = .....
pstmt = conn.prepareStatement("select a from ..."); // ....(1)
rs = pstmt.executeQuery();
.....
rs.close();
pstmt = conn.prepareStatement("select b from ..."); // <--- (2) !!!
rs = pstmt.executeQuery();
....
}
finally{
if ( rs != null ) try {rs.close();}catch(Exception e){}
if ( pstmt != null ) try{pstmt.close();}catch(Exception e){} // <--- (3)
if ( conn != null ) ...<releaseConnection()>...;
}
Statement의 인스턴스는 conn.createStatement() 시에 할당되어 지는 반면,
PreparedStatement는 conn.prepareStatement("..."); 시에 할당되어 집니다. 위의 경우에서
설령 마지막 finally 절에서 pstmt.close() 를 하고 있기는 하지만, (1)번에서 할당되어진
pstmt 는 (2)에서 엎어쳤기 때문에 영원히 close() 되지 않게 됩니다. 따라서, 다음과
같이 코딩되어야 한다는 것은 자명합니다.
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = .....
pstmt = conn.prepareStatement("select a from ..."); // ....(1)
rs = pstmt.executeQuery();
.....
rs.close();
pstmt.close(); // <------- !!!!! 이처럼 여기서 먼저 close() 해야지요.
pstmt = conn.prepareStatement("select b from ..."); // <--- (2)
rs = pstmt.executeQuery();
....
}
finally{
if ( rs != null ) try {rs.close();}catch(Exception e){}
if ( pstmt != null ) try{pstmt.close();}catch(Exception e){} // <--- (3)
if ( conn != null ) ...<releaseConnection()>...;
}
혹은 다음과 같이 서로 다른 두개의 PreparedStatement를 이용할 수도 있습니다.
Connection conn = null;
PreparedStatement pstmt1 = null;
ResultSet rs1 = null;
PreparedStatement pstmt2 = null;
ResultSet rs2 = null;
try {
conn = .....
pstmt1 = conn.prepareStatement("select a from ..."); // ....(1)
rs1 = pstmt1.executeQuery();
.....
pstmt2 = conn.prepareStatement("select b from ..."); // <--- (2)
rs2 = pstmt2.executeQuery();
....
}
finally{
if ( rs1 != null ) try {rs1.close();}catch(Exception e){}
if ( pstmt1 != null ) try{pstmt1.close();}catch(Exception e){} // <--- (3)
if ( rs2 != null ) try {rs2.close();}catch(Exception e){}
if ( pstmt2 != null ) try{pstmt2.close();}catch(Exception e){} // <--- (4)
if ( conn != null ) ...<releaseConnection()>...;
}
4.6.2 아래는 앞서의 4.6.1과 같은 맥락인데, for loop 안에서 사용된 경우입니다.
Connection conn = null;
PreparedStatement pstmt = null;
try {
conn = ...<getConnection()>...;
for(int i=0;i<10;i++){
pstmt = conn.prepareStatement("update .... ?... where id = ?"); //... (1)
pstmt.setString(1,"xxxx");
pstmt.setString(2,"id"+(i+1) );
int affected = pstmt.executeUpdate();
if ( affected == 0 ) throw new Exception("NoAffected");
else if ( affedted > 1 ) throw new Exception("TooManyAffected");
}
}
finally{
if ( pstmt != null ) try {pstmt.close();}catch(Exception e){} // ...(2)
if ( conn != null ) ...<releaseConnection()>...;
}
이 경우가 실제 프로젝트 performace 튜닝을 가 보면 종종 발견되는 잘못된
유형 중의 하나입니다. 핵심은 pstmt.prepareStatement("update..."); 문장을
수행할 때 마다 내부적으로 pstmt 가 새로 할당된다는 것에 있습니다.
결국, (1)번 문장이 for loop 을 돌면서 9개는 pstmt.close()가 되지 않고, 마지막
하나의 pstmt 만 finally 절의 (2)번에서 close 되지요...
따라서 다음처럼 고쳐져야 합니다.
Connection conn = null;
PreparedStatement pstmt = null;
try {
conn = ...<getConnection()>...;
pstmt = conn.prepareStatement("update .... ?... where id = ?");
for(int i=0;i<10;i++){
pstmt.clearParameters();
pstmt.setString(1,"xxxx");
pstmt.setString(2,"id"+(i+1) );
int affected = pstmt.executeUpdate();
if ( affected == 0 ) throw new Exception("NoAffected");
else if ( affedted > 1 ) throw new Exception("TooManyAffected");
}
}
finally{
if ( pstmt != null ) try {pstmt.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
PreparedStatement 라는 것이, 한번 파싱하여 동일한 SQL문장을 곧바로 Execution할 수
있는 장점이 있는 것이고, 궁극적으로 위와 같은 경우에 효과를 극대화 할 수 있는
것이지요.
어느 개발자의 소스에서는 위의 경우를 다음과 같이 for loop 안에서 매번
conn.prepareStatement(...)를 하는 경우를 보았습니다.
Connection conn = null;
try {
conn = ...<getConnection()>...;
for(int i=0;i<10;i++) {
PreparedStatement pstmt = null;
try{
pstmt = conn.prepareStatement("update .... ?... where id = ?");
pstmt.clearParameters();
pstmt.setString(1,"xxxx");
pstmt.setString(2,"id"+(i+1) );
int affected = pstmt.executeUpdate();
if ( affected == 0 ) throw new Exception("NoAffected");
else if ( affedted > 1 ) throw new Exception("TooManyAffected");
}
finally{
if ( pstmt != null ) try {pstmt.close();}catch(Exception e){}
}
}
}
finally{
if ( conn != null ) ...<releaseConnection()>...;
}
위 경우는 장애관점에서 보면 사실 별 문제는 없습니다. 적어도 닫을 건 모두 잘 닫고
있으니까요. 단지 효율성의 문제가 대두될 수 있을 뿐입니다.
4.7 생각해 보면, Statement 나 PreparedStatement 가 close() 되지 않는 유형은
여러가지가 있습니다. 그러나 열려진 Statement는 반드시 close()되어야 한다라는
단순한 사실에 조금만 신경쓰시면 어떻게 프로그래밍이 되어야 하는지 쉽게
감이 오실 겁니다. 단지 신경을 안쓰시니 문제가 되는 것이지요...
Statement 를 닫지 않는 실수를 한 코드가 400-1000여개의 전 어플리케이션을 통털어
한두군데에 숨어 있는 경우가 제일 찾아내기 어렵습니다. 한두번 Statement 를
close 하지 않는다고 하여 곧바로 문제로 나타나지 않기 때문입니다.
하루나 이틀, 혹은 며칠지나서야, Oracle 의 경우, "maximum open cursor exceed"
에러를 내게 됩니다. oracle 의 경우, 위와 같은 에러를 conn.createStatement()시에
발생하므로 (경우에 따라) 큰 문제로 이어지지는 않습니다. 찾아서 고치면 되니까요.
반면, DB2 의 경우는 메모리가 허용하는 한도까지 지속적인 메모리 증가를 야기합니다.
급기야 "핸들(handle)이 더이상 없습니다", "응용프로그램 힙(heap)에 명령문을
처리하기 위해 사용 가능한 저장영역이 충분하지 않습니다", "유효하지 않은 명령문
핸들 또는 명령문이 닫혔습니다" 등과 같은 에러를 내지만, 여기서 그치는 것이 아니라
새로운 connection 을 맺는 시점에 SIGSEGV 를 내면 crashing 이 일어납니다.
java.lang.OutOfMemoryError 가 발생하기 때문이지요.
Oracle 의 경우도 사실 상황에 따라 심각할 수 있습니다. 예를 들어, 어떤 개발자가
"maximum open cursor exceed"라는 Oracle SQL 에러 메세지를 만나고는 자신이
코딩을 잘못한 것은 염두에 두지 않고, 무조건 DBA에게 oraXXX.ini 파일에서
OPEN_CURSORS 값을 올려달라고 요청하고, DBA는 그 조언(?)을 충실히 받아들여
Default 50 에서 이를 3000 으로 조정합니다. 여기서 문제는 깊숙히(?) 숨겨집니다.
close() 안된 Statement 가 3000 회에 도달하지 전까진 아무도 문제를 인식하지
못하기 때문이죠. 그러나, Statement가 하나씩 close()되지 않은 갯수에 비례하여
Oracle 엔진의 메모리 사용은 자꾸만 증가하고, 전체적인 성능저하를 야기하지만,
이를 인식하기란 막상 시스템을 오픈하고 나서 3-4일이 지난 후에 "DB성능이 이상하네,
응답속도가 느리네" 하면서 또 한번의 "maximum open cursor exceed" 메세지를
확인하고 난 뒤의 일이 되곤 합니다.
에러가 없는 정상적인 로직 flow 에서는 대부분 Statement가 잘 닫힐 겁니다. 그러나,
어떤 이유에서건 아주 드물게 Runtime Exception 이 발생하여 exception throwing으로
인해 "stmt.close()"를 타지 않는 경우가 제일 무섭지요. 정말 무섭지요...
Statement, PreparedStatement, CallableStatement 모두 마찬가지 입니다.
5. close() 를 할 땐 제대로 해야 한다!!
5.1 다음과 같은 프로그램 형식을 생각할 수 있습니다.
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try{
conn = ...<getConnection()>...; //.......(1)
stmt = conn.createStatement(); //.............(2)
rs = stmt.executeQuery("select ....."); // .....(3)
while(rs.next()){
......
}
}
finally {
try {
rs.close(); //........(4)
stmt.close(); //......(5)
...<releaseConneciton()>...; //......(6)
}catch(Exception e){}
}
위에선 뭐가 잘못되었을까요? 다 제대로 한듯 한데....
finally 절에서 rs, stmt, conn 을 null check 없이, 그리고 동일한 try{}catch 절로
실행하고 있습니다.
예를 들어, (1), (2) 번을 거치면서 conn 과 stmt 객체까지는 제대로 수행되었으나
(3)번 Query문장을 수행하는 도중에 SQLException 이 발생할 수 있습니다. 그러면,
finally 절에서 (4) 번 rs.close()를 수행하려 합니다. 그러나, executeQuery()가
실패 했기 때문에 rs 의 reference 는 null 이므로 rs.close() 시에
NullPointerException 이 발생합니다. 결국 정작 반드시 수행되어야할 (5)번, (6)번이
실행되지 않습니다. 따라서 반드시(!) 다음과 같은 형식의 코딩이 되어야 합니다.
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try{
conn = ...<getConnection()>...;
stmt = conn.createStatement();
rs = stmt.executeQuery("select .....");
while(rs.next()){
......
}
}
catch(Exception e){
....
}
finally {
if ( rs != null ) try{rs.close();}catch(Exception e){}
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
같은 맥락으로 PreparedStatement 를 사용할 경우도, 다음과 같은 코딩은 잘못되었습니다.
Connection conn = null;
PreparedStatement pstmt = null;
try{
conn = ...<getConnection()>...; //.......(1)
pstmt = conn.prepareStatement("ddelete from EMP where empno=7942"); //...(2)
int k = pstmt.executeUpdate(); // .....(3)
......
}
finally {
try {
pstmt.close(); //......(4)
...<releaseConneciton()>...; //......(5)
}catch(Exception e){}
}
왜냐면, SQL문장에 오타가 있었고, 이는 prepareStatement("ddelete..")시점에 에러가
발생하여 pstmt 가 여전히 null 인 상태로 finally 절로 분기되기 때문인 것이죠.
5.2.0 앞서 4.2에서도 언급했지만, java.sql.Statement의 executeQuery()에 의한 ResultSet은
Statement 가 close 될때 자원이 같이 해제되므로 다음과 같이 하여도 그리 문제가 되진
않습니다.
Connection conn = null;
Statement stmt = null;
//ResultSet rs = null;
try{
conn = ...<getConnection()>...;
stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("select .....");
while(rs.next()){
......
}
rs.close(); // <---- !!!
}
catch(Exception e){
....
}
finally {
//if ( rs != null ) try{rs.close();}catch(Exception e){}
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
5.2.1 그러나 PreparedStatement에 의한 ResultSet close()는 얘기가 다를 수 있습니다.
(2002.06.11 추가 사항)
많은 분들이, "아니 설령 ResultSet를 close하지 않았더라도 Statement/PreparedStatement를
close하면 함께 ResultSet로 close되는 것 아니냐, JDBC 가이드에서도 그렇다고
나와 있다, 무슨 개뿔같은 소리냐?" 라구요.
그러나, 한가지 더 이해하셔야 할 부분은, 웹스피어, 웹로직과 같은 상용 웹어플리케이션
서버들은 성능향상을 위해 PreparedStatement 및 심지어 Statement에 대한 캐싱기능을
제공하고 있습니다. pstmt.close() 를 하였다고 하여 정말 해당 PreparedStatement가
close되는 것이 아니라, 해당 PreparedeStatement가 생겨난 java.sql.Connection당 지정된
개수까지 웹어플리케이션서버 내부에서 reference가 사라지지 않고 캐시로 남아 있게 됩니다.
결국, 연관된 ResultSet 역시 close()가 되지 않은 채 남아있게 되는 것이지요. 명시적인
rs.close()를 타지 않으면, 웹어플리케이션서버의 JVM내부 힙영역 뿐만아니라, 쿼리의 결과로
데이타베이스에서 임시로 만들어진 메모리데이타가 사라지지 않는 결과를 낳게 됩니다.
특히 ResultSet이 닫히지 않으면 DB에서의 CURSOR가 사라지지 않습니다.
또한, CURSOR를 자동으로 닫거나 닫지 않는 등의 옵션은 WAS마다 WAS의 DataSource설정에서
CORSOR 핸들링에 대한 별도의 옵션을 제공하게 되며 특히 아래 [항목6]에서 다시 언급할
nested sql query 처리시에 민감한 반응을 하게 됩니다.
따라서, 앞서의 코딩 방법을 반드시 다음처럼 ResultSet도 close하시기를 다시금 정정하여
권장 드립니다.
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null; // <---- !!!
try{
conn = ...<getConnection()>...;
pstmt = conn.prepareStatement("select .....");
rs = pstmt.executeQuery(); // <----- !!!
while(rs.next()){
......
}
//rs.close(); // <---- !!!
}
catch(Exception e){
....
}
finally {
if ( rs != null ) try{rs.close();}catch(Exception e){} // <---- !!!
if ( pstmt != null ) try{pstmt.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
PS: 웹어플리케이션서버에서의 PreparedStatement 캐싱기능에 관한 부분은 아래의 글들을
참조하세요.
Connection Pool & PreparedStatement Cache Size
http://www.javaservice.net/~java/bbs/read.cgi?m=appserver&b=was&c=r_p&n=995572195
WebLogic에서의 PreparedStatement Cache -서정희-
http://www.javaservice.net/~java/bbs/read.cgi?m=dbms&b=jdbc&c=r_p&n=1023286823
5.3 간혹, 다음과 같은 코딩은 문제를 야기하지 않을 것이라고 생각하는 분들이 많습니다.
finally{
try{
if ( stmt != null ) stmt.close();
if ( conn != null ) conn.close();
}catch(Exception e){}
}
저명한 많은 책에서도 위처럼 코딩되어 있는 경우를 종종봅니다. 맞습니다. 특별히 문제성이
있어보이지는 않습니다. 그러나, 간혹 웹어플리케이션서버의 Connection Pool과 연계하여
사용할 땐 때론 문제가 될 때도 있습니다. 즉, 만약, stmt.close()시에 Exception이 throw
되면 어떻게 되겠습니까?
아니 무슨 null 체크까지 했는데, 무슨 Exception이 발생하느냐고 반문할 수도 있지만,
오랜 시간이 걸리는 SQL JOB에 빠져 있다가 Connection Pool의 "Orphan Timeout"이 지나
자동으로 해당 Connection을 Pool에 돌려보내거나 혹은 특별한 marking처리를 해 둘 수
있습니다. 이 경우라면 stmt.close()시에 해당 웹어플리케이션서버에 특화된 Exception이
발생하게 됩니다. 그렇게 되면 conn.close()를 타지 못하게 되는 사태가 벌어집니다.
따라서, 앞서 하라고 권장한 형식으로 코딩하세요.
6. Nested (Statemet) SQL Query Issue !!
6.1 아래와 같은 코딩을 생각해 보겠습니다.
Connection conn = null;
Statement stmt = null;
try{
conn = ...<getConnection()>...;
stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("select deptno ...where id ='"+ id +"'");
while(rs.next()){
String deptno = rs.getString("deptno");
stmt.executeUpdate(
"update set dept_name = ... where deptno = '"+ deptno +"'"
);
......
}
rs.close();
}
catch(Exception e){
....
}
finally {
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
위 코드는 사실 실행하자 말자 다음과 같은 에러를 만나게 됩니다.
DB2 : -99999: [IBM][CLI Driver] CLI0115E 커서 상태가 유효하지 않습니다.
SQLSTATE=24000
Oracle :
에러는 두번째 while(rs.next()) 시에 발생합니다. 왜냐면, Statement가 nested하게
실행된 executeUpdate() 에 의해 엎어쳐 버렸기 때문입니다. ResultSet 은
Statement와 밀접하게 관련이 있습니다. ResultSet은 자료를 저장하고 있는 객체가
아니라, 데이타베이스와 step by step으로 상호 통신하는 Interface 일 뿐이기 때문입니다.
따라서 위 코드는 다음처럼 바뀌어져야 합니다.
Connection conn = null;
Statement stmt1 = null;
Statement stmt2 = null;
try{
conn = ...<getConnection()>...;
stmt1 = conn.createStatement();
stmt2 = conn.createStatement();
ResultSet rs = stmt1.executeQuery("select deptno ...where id ='"+ id +"'");
while(rs.next()){
String deptno = rs.getString("deptno");
stmt2.executeUpdate(
"update set dept_name = ... where deptno = '"+ deptno +"'"
);
......
}
rs.close();
}
catch(Exception e){
....
}
finally {
if ( stmt1 != null ) try{stmt1.close();}catch(Exception e){}
if ( stmt2 != null ) try{stmt2.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
즉, ResultSet에 대한 fetch 작업이 아직 남아 있는 상태에서 관련된 Statement를
또다시 executeQuery()/executeUpdate() 를 하면 안된다는 것입니다.
PS: IBM WebSphere 환경일 경우, 아래의 글들을 추가로 확인하시기 바랍니다.
349 Re: Function sequence error (Version 3.x)
http://www.javaservice.net/~java/bbs/read.cgi?m=appserver&b=was&c=r_p&n=991154615
486 WAS4.0x: Function sequence error 해결
http://www.javaservice.net/~java/bbs/read.cgi?m=appserver&b=was&c=r_p&n=1015345459
7. executeUpdate() 의 결과를 비즈니스 로직에 맞게 적절히 활용하라.
7.1 아래와 같은 코딩을 생각해 보겠습니다.
public void someMethod(String empno) throws Exception {
Connection conn = null;
Statement stmt = null;
try{
conn = ...<getConnection()>...;
stmt = conn.createStatement();
stmt.executeUpdate(
"UPDATE emp SET name='이원영' WHERE empno = '" + empno + "'"
);
}
finally {
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
}
사실 흔히들 이렇게 하십니다. 별로 잘못된 것도 없어보입니다. 근데, 만약
DB TABLE에 해당 empno 값이 없으면 어떻게 될까요? SQLException 이 발생
하나요? 그렇지 않죠? 아무런 에러없이 그냥 흘러 내려 옵니다. 그러면, Update를
하러 들어 왔는데, DB에 Update할 것이 없었다면 어떻게 해야 합니까? 그냥 무시하면
되나요? 안되죠.. 따라서, 다음 처럼, 이러한 상황을 이 메소드를 부른 곳으로
알려 줘야 합니다.
public void someMethod(String empno) throws Exception {
Connection conn = null;
Statement stmt = null;
try{
conn = ...<getConnection()>...;
stmt = conn.createStatement();
int affected = stmt.executeUpdate(
"UPDATE emp SET name='이원영' WHERE empno = '" + empno + "'"
);
if ( affected == 0 ) throw new Exception("NoAffectedException");
else if ( affected > 1 ) throw new Exception("TooManyAffectedException");
}
finally {
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
}
물론 이러한 부분들은 해당 비즈니스로직이 뭐냐에 따라서 다릅니다. 그것을 무시케
하는 것이 비즈니스 로직이었다면 그냥 무시하시면 되지만, MIS 성 어플리케이션의
대부분은 이처럼 update 나 delete 쿼리의 결과에 따라 적절한 처리를 해 주어야
할 것입니다.
8. Transaction 처리를 할 땐 세심하게 해야 한다.
단, 아래는 웹어플리케이션서버의 JTA(Java Transaction API)기반의 트렌젝션처리가 아닌,
java.sql.Connection에서의 명시적인 conn.setAutoCommit(false) 모드를 통한 트렌젝션처리에
대해서 언급 하고 있습니다.
8.1 Non-XA JDBC Transaction(명시적인 java.sql.Connection/commit/rollback)
Connection conn = null;
Statement stmt = null;
try{
conn = ...<getConnection()>...;
stmt = conn.createStatement();
stmt.executeUpdate("UPDATE ...."); // -------- (1)
stmt.executeUpdate("DELETE ...."); // -------- (2)
stmt.executeUpdate("INSERT ...."); // -------- (3)
}
finally {
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
if ( conn != null ) ...<releaseConnection()>...;
}
위와 같은 코딩은 아무리 비즈니스적 요구가 간소하더라도, 실 프로젝트에서는
있을 수가 없는 코딩입니다.(JTS/JTA가 아닌 명시적인 Transaction 처리시에..)
다들 아시겠지만, (1), (2) 번까지는 정상적으로 잘 수행되었는데, (3)번문장을
수행하면서 SQLException 이 발생하면 어떻게 되나요? (1),(2)은 이미 DB에 반영된
채로 남아 있게 됩니다. 대부분의 비즈니스로직은 그렇지 않았을 겁니다.
"(1),(2),(3)번이 모두 정상적으로 수행되거나, 하나라도 잘못되면(?) 모두 취소
되어야 한다"
가 일반적인 비즈니스적 요구사항이었을 겁니다. 따라서, 다음처럼 코딩 되어야
합니다.
Connection conn = null;
Statement stmt = null;
try{
conn = ...<getConnection()>...;
conn.setAutoCommit(false);
stmt = conn.createStatement();
stmt.executeUpdate("UPDATE ...."); // -------- (1)
stmt.executeUpdate("DELETE ...."); // -------- (2)
stmt.executeUpdate("INSERT ...."); // -------- (3)
conn.commit(); // <-- 반드시 try{} 블럭의 마지막에 와야 합니다.
}
catch(Exception e){
if ( conn != null ) try{conn.rollback();}catch(Exception ee){}
// error handling if you want
throw e; // <--- 필요한 경우, 호출한 곳으로 Exception상황을 알려줄
// 수도 있습니다
}
finally {
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
// in some connection pool, you have to reset commit mode to "true"
if ( conn != null ) ...<releaseConnection()>...;
}
8.2 auto commit mode 를 "false"로 셋팅하여 명시적인 Transaction 관리를 할 때,
정말 조심해야 할 부분이 있습니다. 예를 들면 다음과 같은 경우입니다.
Connection conn = null;
Statement stmt = null;
try{
conn = ...<getConnection()>...;
conn.setAutoCommit(false);
stmt = conn.createStatement();
stmt.executeUpdate("UPDATE ...."); // ----------------------- (1)
ResultSet rs = stmt.executeQuery("SELECT ename ..."); // ---- (2)
if ( rs.next() ) {
conn.commit(); // ------------------- (3)
}
else {
conn.rollback(); // ----------------- (4)
}
}
finally {
if ( rs != null ) try{rs.close();}catch(Exception e){}
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
// in some connection pool, you have to reset commit mode to "true"
if ( conn != null ) ...<releaseConnection()>...;
}
코드가 왜 위처럼 됐는지는 저도 모르겠습니다. 단지 비즈니스가 그러했나보죠..
문제는 만약, (2)번 executeQuery()문장을 수행하면서 SQLException 이나 기타의
RuntimeException 이 발생할 때 입니다.
commit() 이나 rollback()을 타지 않고, finally 절로 건너 뛰어 Statement를
닫고, connection 은 반환됩니다. 이때, commit() 이나 rollback()이 되지 않은채
(1)번 UPDATE 문이 수행된채로 남아 있게 됩니다. 이는 DB LOCK을 점유하게
되고, 경우에 따라 다르겠지만, 다음번 요청시에 DB LOCK으로 인한 hang현상을
초래할 수도 있습니다.
일단 한두개의 어플리케이션이 어떠한 이유였든, DB Lock 을 발생시키면, 해당
DB에 관련된 어플리케이션들이 전부 응답이 없게 됩니다. 이 상황이 조금만
지속되면, 해당 waiting 을 유발하는 요청들이 어플리케이션서버의 최대 동시
접속처리수치에 도달하게 되고, 이는 전체 시스템의 hang현상으로 이어지게
되는 것이죠..
따라서, 비즈니스 로직이 어떠했든, 반드시 지켜져야할 사항은 다음과 같습니다.
"conn.setAutoComm(false); 상태에서 한번 실행된 Update성 SQL Query는 이유를
막론하고 어떠한 경우에도 commit() 이나 rollback() 되어야 한다."
위의 경우라면 다음처럼 catch 절에서 rollback 시켜주는 부분이 첨가되면 되겠네요.
Connection conn = null;
Statement stmt = null;
try{
conn = ...<getConnection()>...;
conn.setAutoCommit(false);
stmt = conn.createStatement();
stmt.executeUpdate("UPDATE ....");
ResultSet rs = stmt.executeQuery("SELECT ename ...");
if ( rs.next() ) {
conn.commit();
}
else {
conn.rollback();
}
}
catch(Exception e){ // <---- !!!!!
if ( conn != null ) try{conn.rollback();}catch(Exception ee){}
throw e;
}
finally {
if ( rs != null ) try{rs.close();}catch(Exception e){}
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
// in some connection pool, you have to reset commit mode to "true"
if ( conn != null ) ...<releaseConnection()>...;
}
8.3 모든 경우의 수를 생각하라.
다음과 같은 경우를 생각해 보겠습니다.
Connection conn = null;
Statement stmt = null;
try{
conn = ...<getConnection()>...;
conn.setAutoCommit(false);
stmt = conn.createStatement();
stmt.executeUpdate("UPDATE ....");
String idx = name.substring(3);
ResultSet rs = stmt.executeQuery("SELECT ename ... where idx=" + idx);
if ( rs.next() ) {
.....
}
rs.close(); rs = null;
stmt.executeUpdate("UPDATE ....");
conn.commit();
}
catch(SQLException e){
if ( conn != null ) try{conn.rollback();}catch(Exception ee){}
throw e;
}
finally {
if ( rs != null ) try{rs.close();}catch(Exception e){}
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
// in some connection pool, you have to reset commit mode to "true"
if ( conn != null ) ...<releaseConnection()>...;
}
잘 찾아 보세요. 어디가 잘못되었습니까? 잘 안보이시죠?
Connection conn = null;
Statement stmt = null;
try{
conn = ...<getConnection()>...;
conn.setAutoCommit(false);
stmt = conn.createStatement();
stmt.executeUpdate("UPDATE ...."); //---- (1)
String idx = name.substring(3); //<------ (2) NullPointerExceptoin ?
ResultSet rs = stmt.executeQuery("SELECT ename ... where idx=" + idx);
if ( rs.next() ) {
.....
}
rs.close(); rs = null;
stmt.executeUpdate("UPDATE ....");
conn.commit();
}
catch(SQLException e){ //<------ (3) 이 부분을 탈까?
if ( conn != null ) try{conn.rollback();}catch(Exception ee){}
throw e;
}
finally {
if ( rs != null ) try{rs.close();}catch(Exception e){}
if ( stmt != null ) try{stmt.close();}catch(Exception e){}
// in some connection pool, you have to reset commit mode to "true"
if ( conn != null ) ...<releaseConnection()>...;
}
위 코드를 보듯, 만약 (1)을 수행 후 (2)번 에서 NullPointerException 이나
ArrayIndexOutOfBoundException이라도 나면 어떻게 되죠? catch(SQLException ...)에는
걸리지 않고 곧바로 finally 절로 건너띄어 버리네요. 그럼 (1)에서 update 된 것은
commit()이나 rollback() 없이 connection 이 반환되네요... ;-)
어떻게 해야 합니까? SQLException만 잡아서 되는 것이 아니라, catch(Exception ...)과
같이 모든 Exception 을 catch해 주어야 합니다.
8.4 위 주석문에서도 언급해 두었지만, Hans Bergsteins 의 DBConnectionManager.java
와 같은 Connection Pool 을 사용할 경우에, 개발자의 코드에서 transaction auto
commit mode 를 명시적으로 "false"로 한 후, 이를 그냥 pool 에 반환하시면,
그 다음 사용자가 pool 에서 그 connection 을 사용할 경우, 여전히 transaction
mode 가 "false"가 된다는 것은 주지하셔야 합니다. 따라서, DBConnectionManger의
release method를 수정하시든지, 혹은 개발자가 명시적으로 초기화한 후 pool 에
반환하셔야 합니다. 그렇지 않을 경우, DB Lock 이 발생할 수 있습니다.
반면, IBM WebSphere 나 BEA WebLogic 과 같인 JDBC 2.0 스펙에 준하는 Connection
Pool을 사용할 경우는 반환할 당시의 transaction mode 가 무엇이었든 간에,
pool 에서 꺼내오는 connection 의 transaction mode는 항상 일정합니다.
(default 값은 엔진의 설정에 따라 달라집니다.)
그렇다고 commit 시키지 않은 실행된 쿼리가 자동으로 commit/rollback 되는 것은
아닙니다. 단지 auto commit 모드만 자동으로 초기화 될 뿐입니다.
PS:WAS의 JTS/JTA 트렌젝션 기반으로 운영될 경우는 명시적으로 commit/rollback되지
않은 트렌젝션은 자동으로 rollback되거나 commit됩니다. default는 WAS 설정에 따라
다를 수 있습니다.
---------------
NOTE: 자바서비스컨설팅의 WAS성능관리/모니터링 툴인 제니퍼(Jennifer 2.0)를 적용하면,
어플리케이션에서 명시적으로 commit/rollback시키지 않고 그대로 반환시킨 어플리케이션의
소스 위치를 실시간으로 감지하여 알려줍니다. 이를 만약 수작업으로 한다면, 수많은 코드
중 어디에서 DB lock을 유발 시키는 코드가 숨어있는지를 찾기가 경우에 따라 만만치 않은
경우가 많습니다.
8.5 XA JDBC Driver, J2EE JTS/JTA
JDBC 2.0, 표준 javax.sql.DataSource를 통한 JDBC Connection을 사용할 경우에,
대부분의 상용WAS제품들은 J2EE의 표준 JTS(Java Transaction Service)/JTA(Java Transaction
API)를 구현하고 있습니다. 특별히, 하나 이상의 데이타베이스에서 2 phase-commit과
같은 XA Protocol를 지원하고 있지요(사실 WAS에서 2PC가 지원되기 시작한 것은 몇년
되지 않습니다. 2PC를 사용하려면 반드시 XA-JDBC Driver가 WAS에 설치되어야 합니다)
샘플 예제는 다음과 같습니다.
...
javax.transaction.UserTransaction tx = null;
java.sql.Connection conn1 = null;
java.sql.Statement stmt1 = null;
java.sql.Connection conn2 = null;
java.sql.Statement stmt2 = null;
java.sql.CallableStatement cstmt2 = null;
try {
javax.naming.InitialContext ctx = new javax.naming.InitialContext();
tx = (javax.transaction.UserTransaction) ctx.lookup("java:comp/UserTransaction");
// 트렌젝션 시작
tx.begin();
// -------------------------------------------------------------------------
// A. UDB DB2 7.2 2PC(XA) Test
// -------------------------------------------------------------------------
javax.sql.DataSource ds1 =
(javax.sql.DataSource)ctx.lookup("java:comp/env/jdbc/DB2");
conn1 = ds1.getConnection();
stmt1 = conn1.createStatement();
stmt1.executeUpdate(
"insert into emp(empno,ename) values(" + empno + ",'Name" + empno + "')"
);
stmt1.executeUpdate(
"update emp set ename = 'LWY" + count + "' where empno = 7934"
);
java.sql.ResultSet rs1 = stmt1.executeQuery("select empno,ename from emp");
while(rs1.next()){
...
}
rs1.close();
// -------------------------------------------------------------------------
// B. Oracle 8.1.7 2PC(XA) Test
// -------------------------------------------------------------------------
javax.sql.DataSource ds2 =
(javax.sql.DataSource)ctx.lookup("java:comp/env/jdbc/ORA8i");
conn2 = ds2.getConnection();
stmt2 = conn2.createStatement();
stmt2.executeUpdate(
"update emp set ename = 'LWY" + count + "' where empno = 7934"
);
java.sql.ResultSet rs2 = stmt2.executeQuery("select empno,ename from emp");
while(rs2.next()){
...
}
rs2.close();
// -------------------------------------------------------------------------
// 트렌젝션 commit
tx.commit();
}
catch(Exception e){
// 트렌젝션 rollback
if ( tx != null ) try{tx.rollback();}catch(Exception ee){}
...
}
finally {
if ( stmt1 != null ) try { stmt1.close();}catch(Exception e){}
if ( conn1 != null ) try { conn1.close();}catch(Exception e){}
if ( stmt2 != null ) try { stmt2.close();}catch(Exception e){}
if ( conn2 != null ) try { conn2.close();}catch(Exception e){}
}
NOTE: 위에서 설명한 하나하나가 제 입장에서 보면 너무나 가슴깊이 다가오는
문제들입니다. 개발하시는 분의 입장에서 보면, 위의 가이드에 조금 어긋났다고
뭐그리 문제겠느냐고 반문하실 수 있지만, 수백본의 소스코드 중에 위와 같은 규칙을
준수하지 않은 코드가 단 하나라도 있다면, 잘 운영되던 시스템이 며칠에 한번씩
에러를 야기하거나 응답이 느려지고 급기야 hang 현상을 초래하는 결과를 가져 옵니다.
정말(!) 그렇습니다.
NOTE: 위에서 사용한 코딩 샘플들은 JDBC Connection Pooling 은 전혀 고려치 않고
설명드렸습니다. 그러했기 때문에 <getConnection()>, <releaseConnection()> 이란
Pseudo 코드로 설명했던 것입니다.
반드시 "서블렛 + JDBC 연동시 코딩 고려사항 -제2탄-" 을 읽어 보세요.
http://www.javaservice.net/~java/bbs/read.cgi?m=devtip&b=servlet&c=r_p&n=968522077
-------------------------------------------------------
본 문서는 자유롭게 배포/복사 할 수 있으나 반드시
이 문서의 저자에 대한 언급을 삭제하시면 안됩니다
================================================
자바서비스넷 이원영
E-mail: javaservice@hanmail.net
PCS:010-6239-6498
================================================ |